人工智能、云计算、大数据等各类数字技术正在交织构建一个全新的虚拟空间,生产、流通、科学、教育、娱乐、社交等等无不因此而变。在技术驱动下,新的数字文明正勃然而兴,突飞猛进的算力变革则是这次文明迭代的重要驱动力之一。自计算机问世以来,在短短的70余年的时间内,其性能从最初的每秒5000次运算发展到如今超级计算机的每秒百亿亿次计算,性能激增数百万亿倍。即便如此,面对蓬勃兴起的生成式人工智能、元宇宙等技术,算力缺口依然巨大。
在浪潮信息,有这样一群工程师们,他们在好奇心的驱动下,通过各种方式寻找算力提升的路径,无论进步大小,自豪感都在驱使着他们继续探索未知,甚至像一个科学家一样琢磨各种跨界的技术,并用于解决各类工程难题。他们具有发散的思维,也有着聚焦的能力,凭借对算力创新的热情与追求,不断拓展数字文明的边界……

高速互连,服务器设计的“艺术”
Yang Yang,浪潮信息AI服务器工程师大军中的一员,他所在的团队负责进行AI服务器系统架构的研发工作,其中的关键是——设计开发出一款具备超高速互连性能的开放加速基板。
“以前,我们在强调怎么样去提高单颗芯片的算力。但是到了大模型时代,模型训练动辄成千上万张卡,单张芯片已经完全无法承载。在新的AI超级计算机形态下,什么样的互连架构才能更好的支撑大模型业务发展,是我们重点研究的一个课题。” Yang Yang认为,实现数千乃至上万颗芯片互连并让它们能够高效协同工作的前提,是解决单个服务器内部芯片的高速直连,这是一切问题的“原点”。
在他们团队的努力下,浪潮信息定义了业界第一个符合OAM(开放加速模块)规范的8卡互连AI系统,这是一个遵循开放计算标准的互连的基板,首次达到了单通道56Gbps速率。这个基板的厚度仅为3.26mm,层数却高达22层,包含了近1000个高速互连差分对。

目前,56Gpbs仍然是开放加速规范下芯片互连的最高速率。Yang Yang表示:“下一步,我们将冲刺112Gbps单通道的高速互连通信,这种级别的速度提升,就相当于我们从5G时代跨步进入了6G时代。”
112Gbps 高速互连技术难点在于,在物理尺寸近乎不变的情况下,要将GPU间的互连速率提升一倍,需要牺牲信噪比。而信噪比的降低带来的影响是巨大的,意味着112Gbps信号对于抖动和噪声的敏感程度更为强烈,即对于信道的串扰、SCD(信号在通过该通道时的差分能量变为共模能量的模态转化量,越低越好。)、PN Skew(内外线路不等长造成的传输差异)、ILD(损耗,线损/阻抗的影响程度,即漂移度)等指标的要求都更为严苛。
这不仅需要更高端的材料支撑,更考验设计的“艺术”。要知道,3-5mm厚度的基板实际上是采用叠层设计,往往包含了十几层甚至几十层PCB板(印刷电路板),每层厚度仅有100微米左右,与一张A4纸相当。而为了保证信号传输质量,每组线路均需要采用差分对设计,即采用长度相等、相位相反的互补信号来传输同一个信号,以减少噪音和EMI(电磁干扰),这将使得布线量增加一倍,对于本就信号布线密度近乎极限的基板来说,无疑是雪上加霜。并且,差分对走线的宽度和间距必须始终保持一致,当在基板上的障碍物,如过孔或较小的器件周围布线时,对设计能力的要求更高。
因此,112Gbps高速互连设计不仅需要寻找更低损耗的树酯、玻璃纤维及更平滑的铜箔,同时也要确保这些材料在加工之后能够符合可靠度的规范,设计与工艺复杂度极高。
在Yang Yang看来,112Gpbs高速互连技术既需要科学的发散,也要做到工程的收敛:通过科学的发散寻找创新的可能性,通过工程的收敛寻找“可行性”。创新的可能性空间包括了材料、工艺、方法、管理运营等等,而可行性则是寻找“最大化或最小化”,是寻找最优解的过程,“就像谈到利润,我们往往都会追求利润最大化而成本最小化,最大化与最小化在很多时候是统一的,目标是一致的。”
Yang Yang团队所从事的工作能够惠及数以百计的芯片创新公司以及更多数量的用户:借助标准化的、性能出色的开放加速基板,芯片公司可以快速的实现产品落地并持续迭代,而用户则可以使用统一的、开放的基础架构,根据业务需要配置不同类型的AI加速芯片,加快创新和创造更好的用户体验。
听音降噪,服务器优化的“浪漫”
一台服务器需要整合超过10000个零部件,其中包括50多类专用芯片;同时还涉及30多个技术方向,例如材料学、热力学、电池技术、流体力学、化学等一系列学科;此外,一台服务器里还会应用超过100种传输协议。在制造中,服务器需要经历30多道流程,使用100多种加工和制造工艺,并对200多个关键过程的控制点进行把控。
如何确保整个系统的可靠性,是一项非常精细且复杂的工程,每一个细节都关乎整体,甚至连声音,也会影响到服务器的可靠性。四五年前,相当数量的数据中心用户几乎都遇到了同一个问题:风扇转速越快,硬盘越有可能出现性能波动,严重时还会直接掉线。
“最开始以为振动是罪魁祸首,后来才发现声音才是始作俑者。” 浪潮信息结构工程师Cathy Wang以女性特有的敏锐,创造出一种独属于工程师的“浪漫”——听音降噪。
团队针对硬盘性能失效问题做了大量的实验,发现风扇产生的噪音一旦达到120分贝,极易造成硬盘磁头偏移、读写效率下降,进而导致扇区失效乃至硬盘报废、服务器宕机。“在结构的领域来说有一个不可调和的矛盾,就是风扇的转速提高之后,它的噪音会向高频段以及大声压这个方向去发展,而且它是这个声音和转速是成5次方的关系在增长的,所以我们看到一个非常明确且快速的风扇的噪音增长的趋势。这个风扇和硬盘之间的冲突的问题,如何站在系统设计的角度,建立硬盘敏感度模型,成为业界厂商探讨的难点。” Cathy Wang介绍说。
不过,虽然找到了问题的根源,但解决问题的过程依然曲折。在尝试过正弦波、1/3倍频程等走不通的路径后,Cathy Wang所在的团队才找到了最合适的噪音带宽,并以混频、扫频的模式模拟出多样化的噪声源,能够测量硬盘在500Hz~10000Hz噪音刺激下的共振频率和声压阀值。基于大量机理性研究和测试,团队发现硬盘性能损失与声压强度间的数学规律,构建出业界首个硬盘敏感度模型,量化出不同硬盘受到各类噪声影响后的性能表现。
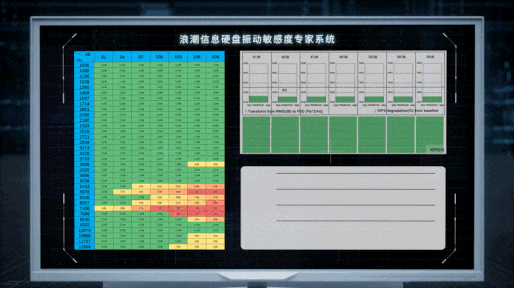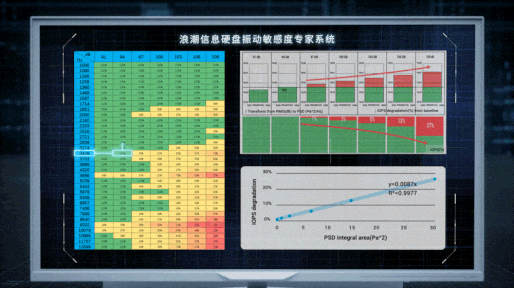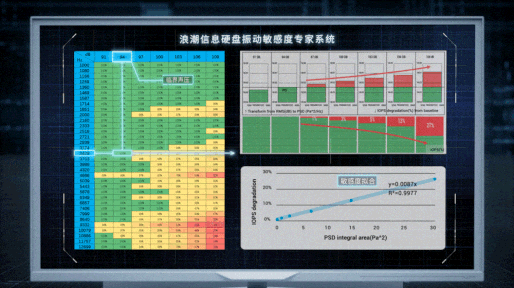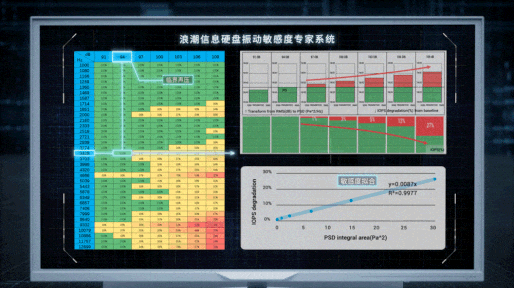
“我们希望通过我们的研究工作,让性能优化从经验主导变为科学主导,借助于不断完善的基础理论、工具与方法,针对特定问题形成标准方案并设计出新的可复用知识。” Cathy Wang说道。
服务器里声音的“黑盒子”就这样被打开了。在确定机箱内真正影响硬盘工作的噪音频谱的基础上,浪潮信息的工程师对服务器系统展开全方位的优化设计。首先从噪声振动的源头入手,通过CFD流体动力学仿真改进风扇的叶片形态,抑制扇叶表面因涡流脱落形成的高频噪音;其次,在机箱内通过设计40多种歌院式的消音结构,有效消除特定的高频噪声;此外,还对硬盘固件中的伺服控制算法进行调整,让硬盘磁头的噪声共振摆动控制在10纳米以内,在提升读写效率、性能翻倍的同时,实现服务器安全运行。
融合架构3.0,服务器架构的“梦想”
大模型时代,当在单机上获得较高算力效率之后,能不能在几百个节点、几千块卡保持相对线性的性能扩展比,已经成为算力集群系统设计和并行策略设计时的关键性因素。在传统计算体系结构中,处理器横向扩展一直是难以突破的瓶颈,寻找新的出路势在必行。
浪潮信息体系结构工程师Lorne Ci 认为:“传统服务器是把所有的IT资源放到一个服务器里面。如果需要更多算力、更多内存、更多IO的话,需要把服务器去做叠加,像我们通常意义上一个大规模的数据中心可能有十几万台,甚至有几十万台服务器。但简单的堆叠只能堆出各种形态和规格的服务器,这对数据中心计算能力的提升,并没有实质性的帮助。需要把服务器IT资源都做成池化的形态,然后通过软件定义的方式来实现资源的动态调配。”
因此,Lorne Ci 团队研究的方向是,创造一种新的体系架构,将硬件设备中的同类资源整合成一个资源池,不同的设备能够任意的整合,再通过软件动态感知业务的资源需求,利用硬件重组的能力来满足各类应用的需要。
浪潮信息将这种新的体系架构命名为“融合架构”,早在2014年就提出这一技术理念,核心在于通过硬件解耦实现资源的物理池化和动态重构,通过软件定义实现业务感知的按需资源组合与配置,满足系统的弹性伸缩和超大规模的持续扩展,实现软硬高度协同发展。浪潮信息将融合架构的发展划分为三个阶段,分别为 “服务器即计算机(Server as a Computer)” ,“机柜即计算机(Rack as a Computer)”以及最终的“数据中心即计算机(Data Center as a Computer)”。

目前融合架构3.0原型系统已经研制成功,实现了计算资源、存储资源、内存资源、异构加速资源等核心IT资源彻底解耦与池化,支持池化资源异步升级、支持细粒度多主机共享高并发存储、亚微秒级远端内存共享访问等特性,可通过软件定义实现“一套系统,N类应用”。
融合架构3.0最核心的就是要做到内存资源池的池化与算力资源池的池化。而如何实现远程内存的调用,实现低延时的快速响应,如何实现缓存一致性……都是内存池化面临的重大挑战。Lorne Ci 介绍说,“现在融合架构基于许多开放总线技术,包括PCIE、CXL等等,共同构建一个大内存系统,构建了一个高速高性能的互联网络,这对于参数量和数据量激增的大模型训练有着巨大价值。”
伴随着融合架构3.0原型系统的研制成功,浪潮信息在融合架构领域完成了重要的突破,实现了整机柜级别的计算、内存、存储与互联等各种IT资源的池化。其中,内存解耦实现了亚微秒级的远端内存访问,并构建出了一种逻辑上可远端共享的内存资源池。这种变化让多台主机可以访问同一个内存池,并最终大幅提高了数据交换的效率。新的架构打破了现有服务器的逻辑架构与应用模式。它以系统设计为中心,可以让数据中心从资源驱动型向业务驱动型转变。面向云计算和人工智能等不同场景,这种新的架构和新的组合方式,让数据中心真正实现了,用一套系统去支撑多类应用。
在如今这个逐渐成型的数字文明时代,计算已经渗透到我们生活的方方面面。不论是在家庭中,商业世界,还是科学研究领域,计算技术都无处不在,这已经成为了我们日常生活的一部分。然而,我们必须认识到,这只是数字文明的起点,计算的重要性将在未来进一步凸显。算力创新将成为数字文明中的火种,它将不断照亮前行的道路。正如昔日的拓荒者冒险前行以开辟新的大陆,今天无数的"算力拓荒人"将持续引领我们进入数字时代的新境界。这些先锋者将科学与工程融合,将"知"与"行"完美结合,以探索广阔而充满想象的未知之地。

在这条通往数字文明的开拓之路上,充满了机遇与挑战,我们需要更多具备跨学科知识的"知行合一"的研发人员,科技工作者,去通过一系列前所未有的解决方案,将计算创新推向新的高度,使其持续闪耀,带领我们走向数字文明的下一个巅峰。

 第七代服务器
第七代服务器













 访问 AIStore
访问 AIStore