技术背景:大内存虚拟机设备透传启动延迟
虚拟机设备透传时存在问题,比如将网卡或者 GPU 这些 pci 设备通过宿主机的 vfio 透传到虚拟机,并且又为虚拟机分配了比较大的内存时,虚拟机的启动时间会明显变慢。特别是分配了几百 G,甚至上 TB 的内存时,就会有比较明显的启动延迟,可能由十几秒延迟到数分钟。由于只有第一次启动时,也就是 qemu 进程启动时才会影响,所以一般来说用户可以接受这个启动延迟,但如果用户有频繁创建销毁虚拟机的需求时就会有比较差的使用体验。
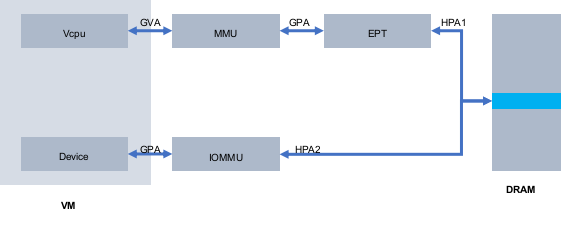
把设备透传到虚拟机内部之后将会使用虚拟机内部的驱动程序对设备进行操作,这里有一个重要的问题是在虚拟机内部该如何进行 DMA 操作,因为 DMA 是不会经过 CPU 的,所以使用的是物理地址,但虚拟机内部看到的物理地址实际上只是宿主机上 qemu 进程申请的虚拟地址,直接用来做 DMA 肯定是不行的。这里就需要借助IOMMU 来实现,虚拟机内 DMA 访问的 GPA,经过 iommu 映射到宿主机上的物理地址 HPA2,另外虚拟机内的驱动程序也可以经过 MMU/EPT,把 GVA 映射为 HPA1,最终需要 HPA1 和 HPA2 这两个物理地址是同一个才能让设备正常运行。(如下图)
为了实现 HPA1 等于 HPA2,需要 GPA 到 HPA 的映射是固定的并进行 iommu 表的建立,vfio 是通过 VFIO_IOMMU_MAP_DMA 命令实现。
后面使用到了 free page reporting 机制,这里介绍下free page reporting 机制的原理,首先该机制提供了回调函数的注册,每隔 2 秒会遍历每个 zone 中的空闲页并调用回调函数进行处理,但只处理 buddy 中高阶内存页,就是 pageblock_order 阶及以上的内存,在 X86 架构下就是处理 9 阶和 10 阶的内存页,也就是 2M 和 4M 的内存页,这样也是保证能够处理 2M 的透明大页。
另一方面在处理时会保证每个 zone 的水线要比最低水线高 64M,因为如果 zone 的水线本身已经够低了,还从 zone 中申请内存,可能就会触发内存回收,这就会影响一些程序的性能。
通内存预清零加速 qemu 进程的内存初始化过程
下图是一个虚拟机启动时的火焰图,这里的虚拟机启动是指 qemu 进程开始执行到虚拟机内部出现 BIOS 界面为止,不包括虚拟机内部的内核加载、服务运行过程,从火焰图可以看到最耗时的函数是 clear_subpage 函数,根据函数调用关系可以看到是从 qemu 端调用了 ioctl 系统调用,这里就是要将虚拟机内存大小的虚拟内存执行 iommu 映射工作,将虚拟地址映射到指定的物理地址上。这其中就需要先将虚拟地址执行 page fault,并将虚拟机地址和物理地址的关系固定下来,再执行 iommu 映射操作。
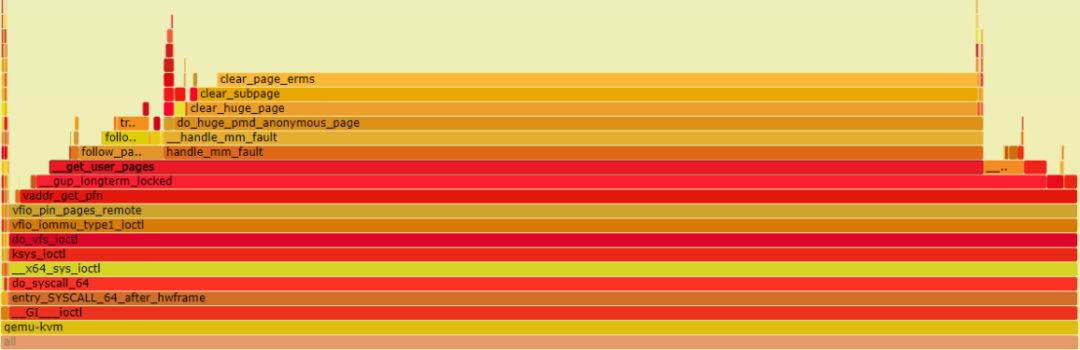
应用程序执行 page fault 时最终都会执行 clear_user_highpage 对内存进行清零操作,这个函数相对来说耗时较长,是虚拟机启动时间慢的重要原因,当然我们可以选择不进行内存清零,但这会把宿主机上的一些敏感信息传递给虚拟机,造成安全影响,所以一般我们需要对内存进行清零。
为了解决内存页清零耗时比较长的问题,我们可以基于 free page reporting 机制实现内存页的预清零,过程比较简单,这里简单说下原理。首先通过 free page reporting 接口注册自己的 hook 函数,然后这个 hook 函数会周期性的被调用,每次调用会将 buddy 中的 2M/4M 空闲页执行清零操作,并在 page 的 flag 上设置清零 flag,最后在应用程序申请的内存触发缺页异常并需要对内存进行清零时,会首先判断该页是否已经设置了清零 flag,如果已设置则跳过耗时较长的清零操作。还有一点就是内存页的清零属于耗时但不紧急的操作,如果当前 CPU 有其它的事情要做,则优先执行别的工作,只有在 CPU 空闲时才执行内存清零。
通过大块内存 pin 降低 qemu 的内存 pin 时间
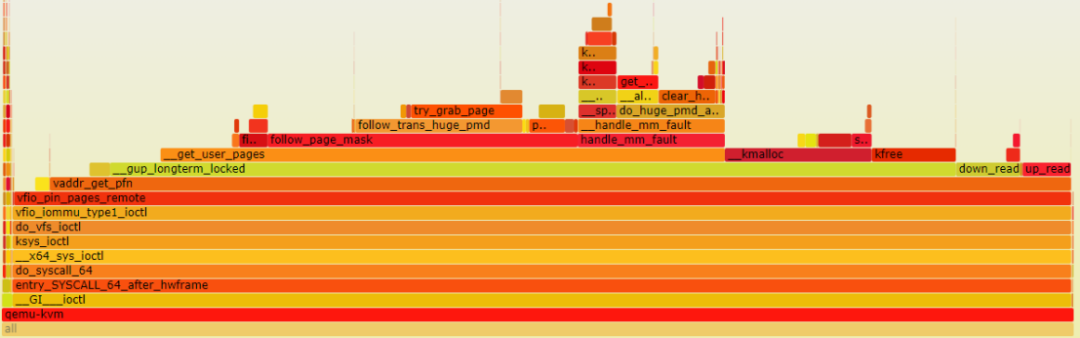
下图是优化了内存页预清零之后的火焰图,可以看到 clear_user_page 函数的执行时间已经非常短了,总体执行时间比较长的几个函数是 follow_page_mask、handle_mm_fault、find_extern_vma,下面就从代码角度来看哪个函数还可以进行优化。

IOMMU_MAP_DMA 的 ioctl 进入内核空间会执行到 vfio_pin_map_dma 函数,在这个函数里会对虚拟机内存大小的虚拟内存进行 iommu map 操作,首先调用 vfio_pin_pages_remote 进行内存 pin 操作,这个函数的返回值 npage 是物理地址连续的N个内存页,然后调用 vfio_iommu_map 执行 iommu map 操作,比如对于 500G 内存的虚拟机来说会执行很多次这两个函数。

vfio_pin_pages_remote 这个函数会返回物理连续的多个内存页,为了实现这功能,每次调用 pin_user_pages_remote 获取一个页,然后判断和上一个页是否物理连续。

前面说的 pin_user_pages_remote 函数执行了很多次,这个函数里主要是调用了 get_user_pages,根据需要 pin 的 page 个数,首先判断相邻的两个虚拟内存页是否属于同一个 vma,如果不是则调用 find_extern_vma 函数获取 vma,这个函数从火焰图来看也是耗时比较长的,下面就是执行 follow_page_mask 获取页表,如果还未分配物理页则调用 page fault。
后面的两个函数执行是无法避免的,现在就看 find_extern_vma 函数,因为虚拟机的物理内存是 qemu mmap 的连续虚拟内存,属于同一个 vma,所以每次如果 pin 多个 page 可以跳过频繁执行的 find_extern_vma。
下面看一下内核社区的优化方案,5.12 内核合入主线,通过修改 vfio 代码实现,commit 说明有 8% 的性能提升。
优化原理是在 pin_user_pages_remote 函数里每次获取 512 个 page,当然这些page可能是不连续的,然后将这 512 个 page 中连续的部分识别出来分别执行iommu,因为我们系统中是开启透明大页的,所以一般来说这 512 个 page 都是物理连续的,只需要执行一次 iommu就可以。

测试结果
测试环境为虚拟机分配了 512G 的内存,做了网卡的设备透传,虚拟机的启动时间计算方法为从 qemu 进程启动开始到出现 grub 界面为止,还有就是内存预清零在最理想的情况下,即当前系统上所有的 free page 已经清零完毕。
最终的测试结果:默认情况下(即开启透明大页),如果只开启大块内存 pin,启动时间从 80 秒降低至 60 秒,如果再开启内存页预清零,启动时间将降低至12 秒。再看下虚拟机内存使用大页内存的情况下的测试结果,在使用 2M 或 1G 大页时开启大块内存 pin 功能时,虚拟机的启动时间基本从 36 秒降低至 18 秒,就算在开启内存页预清零,启动时间也没有变化,因为内存预清零不能作用于标准大页。
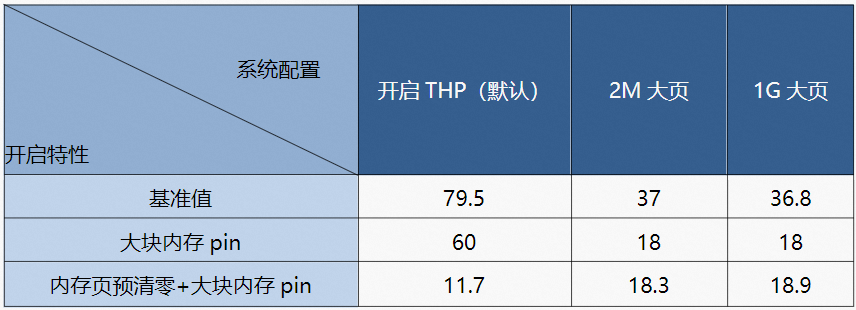
虚拟机分配 512G 内存。
时间计算方法:time virsh start testvm,时间为从 qemu 启动到出现 grub 界面为止。
内存预清零在最理想情况下,即当前系统上所有 free page 已经清零完毕。


售前咨询


售后服务

回到顶部
 售前咨询热线:400-860-6708
售前咨询热线:400-860-6708 售后服务热线:400-860-0011
售后服务热线:400-860-0011 7*24小时服务
7*24小时服务