本文在浪潮信息云峦服务器操作系统KeyarchOS环境下,开展了TCP大数据包通信传输技术的应用实践,在提升吞吐量、降低时延方面作用进行了验证。
随着云计算、大数据、人工智能等技术的快速发展,数据呈现出爆发式增长趋势,同时驱动着算力持续提升,然而,传统DRAM并未实现同步扩展以满足应用需求,应用对内存容量和带宽不断提高的需求,推动着内存扩展技术不断发展,在此背景下,CXL成为解决内存扩展瓶颈的最有前景的技术;与DRAM内存相比,扩展内存面临高延迟、低带宽的技术挑战,为了解决这些挑战,分层内存技术应运而生。
1 背景
网络性能瓶颈:为何CPU比NIC更关键?
在网络性能认知中存在一种直观倾向:认为网卡是决定性能的核心因素。但在实际优化场景中,CPU往往才是真正的瓶颈,这一点在“小包场景”下体现得尤为明显:网卡的带宽(如100G、400G)是硬件固有能力,但数据传输时,每个数据包都需要CPU处理协议栈逻辑(如TCP/IP头部解析、校验和计算、路由决策、连接状态维护等)。
小包场景中,要达到网卡的最大带宽,需要处理的数据包数量会激增,如100G带宽下,64字节小包的每秒处理量约为1.9亿个,此时CPU的处理资源会因高频中断和协议栈处理开销迅速耗尽,导致CPU先于网卡达到瓶颈,网卡带宽无法重复利用。
现有Offload技术:减少CPU负担的基础
为减轻CPU处理压力,现有内核和网卡已通过“卸载(Offload)”技术减少CPU的包处理量,典型的包括 TSO、GSO、GRO:
传统包大小的限制:64K
现有offload技术通过将大包卸载到硬件或延迟执行的方式有效减轻了CPU处理压力,但支持的大包长度存在限制。内核协议栈处理的数据包最大支持64K,IP协议头部的“Total Length”字段为16位,其最大值为2^16-1=65535 字节(约 64KB),是IP数据包的理论最大长度限制。
BIG TCP的本质是通过“增大内核处理的数据包大小(超过64K)”来减少 CPU的包处理总量,从而释放高速网络(100G以上)的性能潜力。其核心逻辑与“小包场景 CPU 瓶颈”直接对应 ——通过减少CPU的 “重复劳动”(每个包的固定处理开销),让CPU和网卡的能力更匹配,最终提升网络吞吐量并降低延迟。
2 BIG TCP实现原理
IPv6
在IPv6包头中,存在长度为32位的hop-by-hop字段可以存储一些特定信息。逐跳选项头(Hop-by-Hop Options Header)是IPv6协议中的一种扩展头部,它允许在数据包传输过程中每个跃点(路由器或节点)都能够读取并处理该头部中的信息。
内核将原先存储数据包长度的字段设置为0,在hop-by-hop字段中存储真实的包长度,使得包的最大大小可以达到4GB。然而,为了安全起见,最大大小限制设置为512K,因此处理的包数量可降低至原来的八分之一。ipv6基本报文头修改如图1所示。需要注意的是,目前只有TCP栈可能会生成超大报文,因此这个扩展头部仅在协议栈内使用,不会通过物理链路发送。
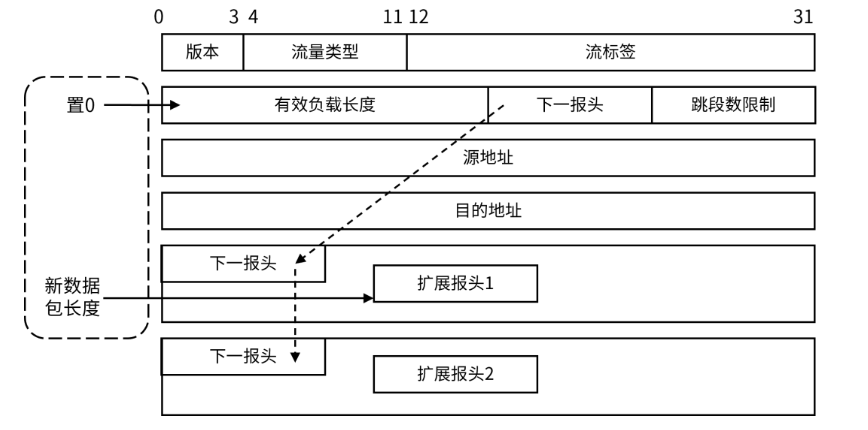
图1:BIG TCP实现原理: IPv6基本报文头
BIG TCP HBH拓展头封装处理:
intip6_xmit(conststructsock *sk,structsk_buff *skb,structflowi6 *fl6,
__u32 mark,structipv6_txoptions *opt,inttclass, u32 priority)
{
...
if(unlikely(seg_len > IPV6_MAXPLEN)) {
hop_jumbo = skb_push(skb, hoplen);
/*nexthdr:指向下一个拓展头*/
hop_jumbo->nexthdr = proto;
/*hdrlen:头部长度(对于逐跳选项头部,通常为0)*/
hop_jumbo->hdrlen =0;
/*tlv_type:TLV类型,设置为IPV6_TLV_JUMBO*/
/*表示这是一个超大报文*/
hop_jumbo->tlv_type = IPV6_TLV_JUMBO;
/*tlv_len:TLV长度,设置为4字节*/
hop_jumbo->tlv_len =4;
/*jumbo_payload_len:超大报文的实际负载长度*/
hop_jumbo->jumbo_payload_len = htonl(seg_len + hoplen);
proto = IPPROTO_HOPOPTS;
seg_len =0;IP6CB(skb)->flags |= IP6SKB_FAKEJUMBO;
}
...
}
IPv4
由于IPv4中没有像IPv6那样的可选拓展头,因此无法在IP头中保存真实的长度信息。因此采用了另一种方法,直接从内核的skb->len计算数据包的真实长度,并将IP头部的tot_len字段设置为0。
3 基于BIG TCP的TCP传输
传统TCP 受限于 IP 头中 16 位长度字段,单个数据包最大为 64KB。BIG TCP 理论上可使数据包长度达到 4GB,目前通常设置为 512KB,相比之前扩大了数倍。
对于IPv6
1)发送:当数据包长度超过65535字节时,将 ipv6 包头的长度字段设置为 0,添加HBH扩展头,从拓展头中读取有效数据长度。若网卡支持TSO,将大数据包卸载到网卡执行分段,分段前移除拓展头。若网卡不支持TSO,在开启GSO情况下,大数据包延迟到出网络协议栈后执行分段,分段前同样需要移除拓展头。
2)接收:GRO合并数据包,当合并后的数据包大小超过65535字节时,添加HBH拓展头,并将IPV6头部的长度字段设置为0。
对于IPv4
1)发送:当数据包长度超过65535字节时,将IP头部的tot_len字段设置为0,表示这是一个超大报文。若网卡支持TSO,将大数据包卸载到网卡执行分段。若网卡不支持TSO,在开启GSO情况下,大数据包延迟到出网络协议栈后执行分段。
2)接收:当合并后的数据包大小超过65535字节时,将IP头部的tot_len字段设置为0,使用skb->len作为数据包的长度,确保超大报文能够在接收路径上正确处理。
具体流程如下图所示:
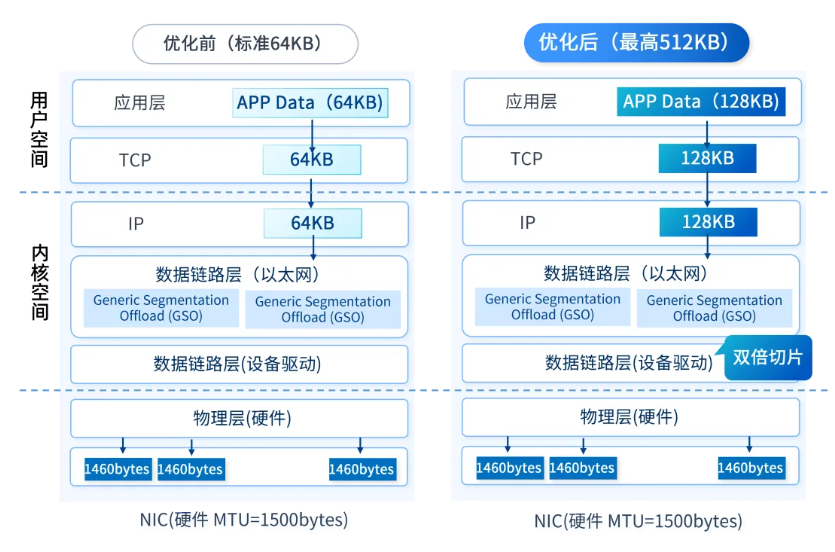
图2:BIG TCP功能架构图
4 基于云峦KeyarchOS的BIG TCP技术实践
基于云峦KeyarchOS 的BIG TCP 技术实践,是在操作系统层面针对高速网络性能优化的深度探索,其核心在于通过适配主流网卡驱动,充分释放BIG TCP在大数据包处理上的优势,最终实现网络性能的跃升。我们的主要工作包括内核的定制以及网卡驱动的适配。
在内核定制环节,我们基于KeyarchOS kernel-4.19内核,回合上游kernel-6.3 BIG TCP的patch。
在驱动适配环节,针对网卡进行了定制化修改,涵盖两个关键方向:
■一方面,修改BIG TCP参数使网卡生效。通过修改驱动,允许用户态直接修改BIG TCP相关的参数来设置网络数据包的大小限制,包括gso_max_size、gro_max_size以及针对IPv4场景的gso_ipv4_max_size、gro_ipv4_max_size。
■另一方面,在网卡分段执行前移除HBH头。在网卡执行分段操作前,驱动需移除IPv6协议报文中的HBH(Hop-by-Hop Options Header,逐跳选项头)的操作,HBH展头仅限于内核网络栈使用,不会在物理链路上发送。
在完成内核对BIG TCP的功能支持及上述驱动适配后,团队基于云峦KeyarchOS操作系统(具体版本为KeyarchOS5.8)开展了系统性的功能验证与性能测试,以验证BIG TCP性能。
■硬件上,采用两块同型号的网卡(网卡_M_MCX516A-GCAT_50G_双光口_PCIE )通过直连方式构建测试链路,排除了中间网络设备(如交换机)对数据传输的干扰,确保测试结果能真实反映BIG TCP在端到端通信中的性能表现。
■系统方面,默认开启GSO/GRO功能,GSO/GRO包大小限制125K,其中64K限制代表不开启BIG TCP;超过64K代表开启BIG TCP后,网络通路中能接收的最大包大小。具体指令如下:
Ipv4:iplinksetdevxxxgso_ipv4_max_size128000gro_ipv4_max_size128000 Ipv6:iplinksetdevxxxgso_max_size128000gro_max_size128000
■软件工具方面,使用业界常用的netperf作为网络性能基准测试工具,可精准测量吞吐量、延迟等关键指标。测试方式为TCP_RR:在同一个tcp连接中,测试对象进行多次request和respose交易。循环执行10次netperf测试,每次请求和响应大小设置为-r80000,8000字节,采集的性能指标包括延时(lat,us)和吞吐量(thp,Mbits/sec)数据,具体指令如下:
foriin{1..10};donetperf-tTCP_RR-H1.1.1.2---r80000,80000-OMIN_LATENCY,P90_LATENCY,P99_LATENCY,MEAN_LATENCY,THROUGHPUT|tail-1;doneIPv6:开启BIG TCP平均吞吐量提升17.33%,延时降低19.7%
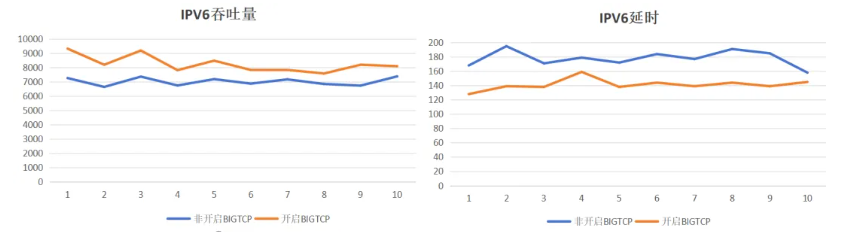
IPv4:开启BIG TCP平均吞吐量提升27.0%,延时降低17.64%
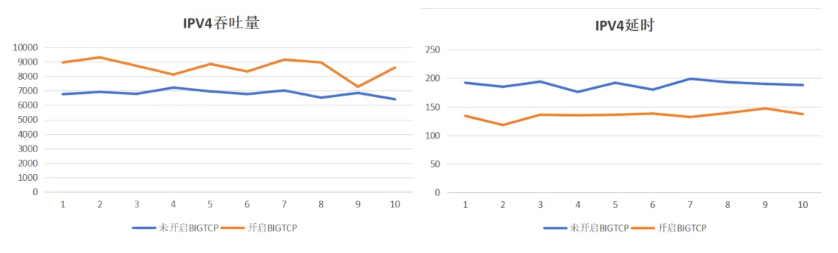
基于云峦KeyarchOS的技术实践结果说明基于BIG TCP技术在网卡带宽高的场景下可显著提升吞吐量,降低延时。


售前咨询


售后服务

回到顶部
 售前咨询热线:400-860-6708
售前咨询热线:400-860-6708 售后服务热线:400-860-0011
售后服务热线:400-860-0011 7*24小时服务
7*24小时服务