AIGC时代的到来,在推动算力需求激增的同时,也推动内存系统向更大容量、更高带宽演进。面对需求端爆发式增长,大容量内存价格不断上涨且持续缺货,已经成为一个困扰行业发展的“现象级”问题。如何在有限的硬件条件下,通过灵活的架构创新与资源优化,突破单机内存容量与带宽的限制,以更具成本效益的方式实现内存能力的扩展,成为化解当前内存困境的关键路径。
日前,浪潮信息推出元脑服务器CXL内存扩展方案,基于元脑服务器NF5280G7,在24条本地DRAM内存的基本配置下,创新性地内置CXL内存扩展卡,单机可扩展16条内存,无需改变现有服务器架构的前提下,即可实现内存容量1TB-4TB区间的灵活扩展。同时,结合元脑服务器操作系统KOS池化内存优化策略,将本地DRAM与CXL扩展内存融合为统一逻辑内存空间,通过低开销、精准的内存冷热监控及动态迁移策略,显著减少CPU等待数据的时间,降低业务的内存访问延迟,使CXL内存达到本地内存的性能。
结合实际场景,当客户配置24条64G本地内存容量不足,需要扩展至少1TB的情况下,若采用传统方案,需将所有本地64GB DRAM内存模组更换为128GB内存,硬件成本高昂且供应紧张。而采用元脑服务器CXL内存扩展方案,客户可维持本地64GB DRAM内存不变,通过配置4张CXL内存扩展卡(共扩展16条64GB内存),在实现同等1TB容量同时,整体采购成本降低超过20%,带宽性能提升18%。

元脑服务器CXL内存扩展方案,单机最高可多扩4TB
AI需求驱动下的大容量内存结构性短缺
当前,生成式AI应用正引发存储需求的爆发式增长。为了追求极致的响应速度和吞吐量,模型推理过程会将海量的中间计算结果(如Transformer模型中的KV Cache)驻留在内存中。以ChatGPT为例,其每分钟处理tokens量从3亿激增至60亿的背后,是所需内存容量近乎线性的同步飙升。视频生成模型的落地,更是将单次生成任务对内存带宽与容量的需求推向新高。这种由AIGC驱动的长周期需求扩张,与上游产业链的产能形成结构性错配,导致存储市场正面临“内存荒”与价格持续上涨的双重压力,不仅推高了企业运营成本,更直接制约了人工智能、实时分析等关键业务的扩展与创新。
在众多依赖大内存的关键业务场景,内存资源的紧缺也同样成为制约效率与性能的瓶颈。以Redis为代表的实时内存数据库,当数据规模超过内存容量的上限时,传统横向分片扩展至多台服务器的方式,会导致网络延迟与架构复杂性;而降级存储至SSD则因介质性能差异导致响应延迟显著上升。尤其在极高并发场景下,内存带宽已成为制约单机性能的核心瓶颈——即使数据全部驻留内存,有限的内存通道带宽也难以满足实时吞吐需求,导致CPU“等待”数据,影响业务吞吐。
在芯片设计领域,EDA后端仿真验证阶段对内存系统提出更为严苛的要求。该过程的数据访问模式主要以顺序访问为主,需要将TB级别的芯片设计数据集同时载入内存,供数百个计算核心进行高并发、低局部性的随机访问与路径分析。这不仅依赖超大内存容量,更对内存聚合带宽提出极高要求,否则会拖慢仿真验证进度,延长芯片研发周期。
元脑服务器CXL内存扩展方案,实现内存灵活拓展与按需分配
针对以上问题,浪潮信息推出的元脑服务器CXL内存扩展方案,为行业提供了一种突破性的内存扩展与性能提升路径。方案基于元脑服务器NF5280G7,创新性地内置CXL内存扩展卡,实现内存容量的弹性扩展,并结合元脑KOS内存优化策略,通过智能的内存池化与数据分层机制,使得扩展的CXL内存在访问热点数据时能够达到接近本地内存的性能。这意味着,在96G、128G大容量内存紧缺的条件下,可以更多的使用64G的DRAM,并通过CXL的内存扩展来的达到大容量内存的需求。方案在实时分析、EDA仿真、大模型推理等大内存应用场景中,均有卓越性能表现。
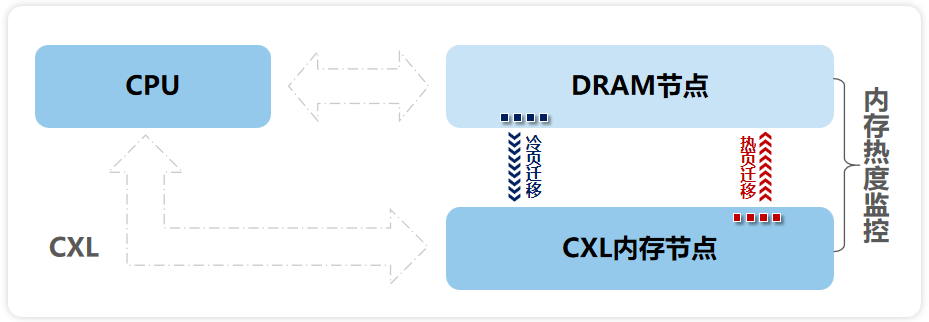
元脑服务器CXL内存扩展方案:内存热度监控
// 场景一:内存数据库应用场景,保障高性能与业务连续性
在高并发场景下(如双十一等大促期间),Redis内存数据库面临极高的读写请求,峰值流量高,需要存储多种数据,使用元脑服务器CXL内存扩展方案可以扩展8通道,无缝扩展可用容量,内存带宽提升18%,提升Redis数据库的读写性能。同时元脑KOS智能将高频访问的“热数据”保留在性能更高的内存区域(包括本地DRAM和CXL内存的热区),而将低频“冷数据”移至成本更优的存储层级,显著减少CPU等待数据的时间,从而降低整体业务延迟。
不同方案组合的数据吞吐量比较
实测表明,在冷热分层功能支持下,本地DRAM+CXL DRAM的性能与纯DRAM的方案基本持平,且达到纯使用SSD扩展方案性能的3倍以上,有效保障了高并发下的业务响应速度与连续性。
// 场景二:EDA仿真场景,平衡容量、带宽与成本
EDA后端物理仿真仿真是典型的内存密集型应用,涉及海量电路数据的并行计算,单个任务常需1-4TB大内存,且对内存带宽要求极高。
本方案通过单机配置多张CXL扩展卡,实现对不同容量内存条的弹性组合与池化管理。例如,在当前96G及以上内存供应紧张的情况下,方案采用“64G本地内存+CXL扩展内存”的配置,不仅有效缓解了对大容量内存条的依赖,更使整体内存成本降低20%。同时,该方案依托元脑KOS的统一池化与智能调度能力,可将本地DRAM与扩展的CXL内存整合为连续、统一的高性能内存地址空间。KOS通过实时监测数据访问模式,动态优化内存带宽分配,确保仿真任务中高频访问的数据优先驻留于低延迟通道,保障了EDA应用所需的大容量内存与高并发带宽,显著加速芯片设计验证全流程。
// 场景三:大模型推理场景,优化KVCache存储成本
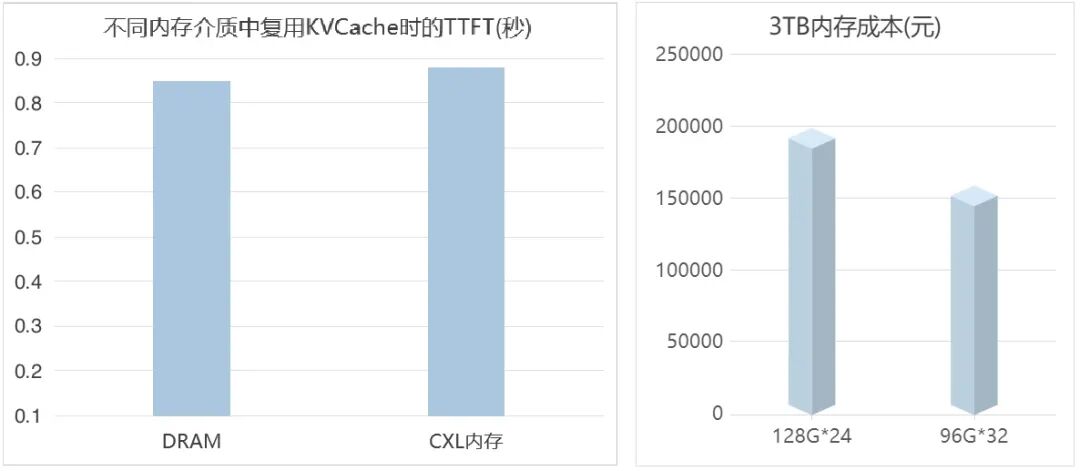
在大模型推理中,海量KVCache存储需求导致内存成本急剧攀升,完全依赖高性能DRAM将极大推高集群部署成本。元脑服务器CXL内存扩展方案通过CXL内存扩展卡构建大容量内存资源池,能将KVCache动态分配至扩展内存中,再结合元脑KOS智能监控,可将KVCache热点数据动态调度至最佳性能层,而将历史或非活跃数据缓存置于成本更优的层级。
元脑服务器CXL内存扩展方案,优化KVCache存储成本
测试结果显示,方案在将每GB内存成本降低约20%的前提下,通过CXL内存复用KVCache,其推理性能与全部使用DRAM的方案差异不超过5%,实现了成本与性能的卓越平衡。
总体来看,浪潮信息元脑服务器CXL内存扩展方案,通过CXL硬件扩展与KOS智能内存管理的深度融合,扩展了本地内存容量,实现了内存资源的高效调度与按需分配,打破了传统内存架构的局限,有效提升了内存资源的利用率与业务吞吐量,为解决行业“内存荒”问题提供了切实可行的技术方案。


售前咨询


售后服务

回到顶部
 售前咨询热线:400-860-6708
售前咨询热线:400-860-6708 售后服务热线:400-860-0011
售后服务热线:400-860-0011 7*24小时服务
7*24小时服务