近日,元脑KOS团队近日向Mooncake社区贡献了CXL单级存储基础功能代码(PR #1365),实现了Put/Get、BatchPut/BatchGet等标准接口的CXL适配,使上层应用可透明启用CXL存储KV Cache。这是Mooncake框架首次原生支持CXL内存介质,为AI智算基础设施开辟了新路径。

开源共建 CXL赋能Mooncake首阶段落地宣传图
大模型推理的性能瓶颈正在经历一场静默的转移——从传统的“算力不足”转向更为隐蔽却同样关键的“内存墙”问题。在长上下文、多并发场景下,注意力机制生成的KVCache需要被反复计算与存储,而这种重复成本极其高昂。业界逐渐意识到,“以存代算”通过KVCache缓存重用可显著降低计算需求。因此,构建高效的KVCache存储系统,已成为释放大模型推理潜能的关键举措。
作为业界领先的分布式KVCache存储引擎,Mooncake通过存储资源重构实现了计算效率的跃迁。它通过构建分布式、多层级的KVCache存储架构,结合多副本机制、零拷贝传输等核心技术,为大模型推理提供了重要的底层基础设施支撑。然而,随着模型规模扩大和上下文长度增长,如何进一步突破内存容量与带宽的物理限制,是当下KVCache管理的热门话题。
CXL(Compute Express Link)作为基于PCIe的高速互连协议,为解决上述问题提供了革命性的技术路径。其核心优势在于通过池化内存实现多主机的共享访问——CXL内存设备可被多主机分别映射至各自的地址空间,无需额外创建数据多副本,即可实现多主机对同一段CXL内存地址的读写。这一共享特性使CXL成为跨机KVCache存储的理想介质,各推理节点可直接通过内存语义访问同一段物理内存,彻底规避了传统 TCP 协议栈的软件开销以及 RDMA 网络传输的复杂交互。
为充分发挥CXL的共享优势,基于元脑KOS的深度优化能力,元脑KOS团队向Mooncake社区贡献CXL内存管理代码。通过这一贡献,Mooncake Store新增了对CXL存储介质的支持,多客户端之间可通过内存语义读写位于CXL池化内存中的KVCache,为推理集群替代TCP/RDMA网络提供了可能性。
CXL单级存储通过Master节点与Client节点的协同,实现了对CXL共享内存的统一管理。整体架构主要包括三个方面。
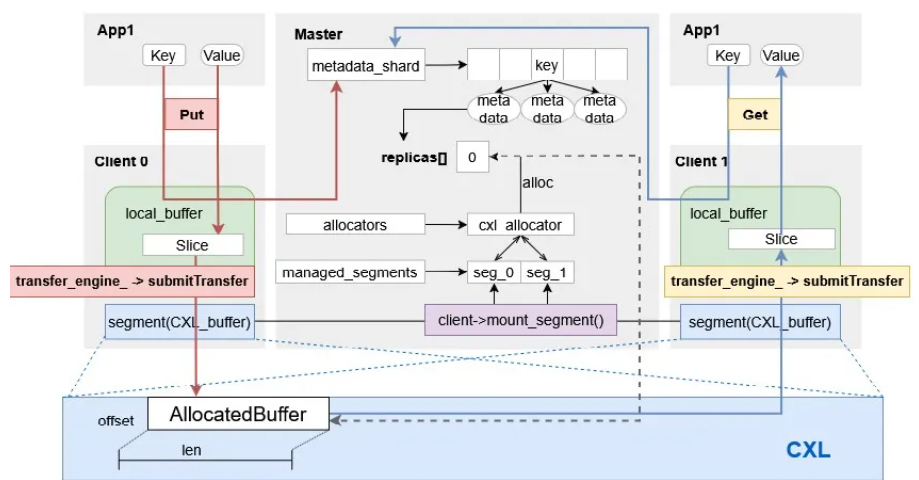
CXL单级存储架构图
■ 基于CXL的Mooncake传输引擎
KOS团队首先实现了基于CXL协议的TransferEngine(PR #670),以cxl_transport作为客户端传输引擎,屏蔽了底层PCIe/CXL协议的复杂性,为上层提供了标准化的数据传输接口。
■全局统一的CXL内存分配器
在存储管理模块中,KOS团队在SegmentManager类中新增了cxl_global_allocator_成员变量,作为统一管理CXL共享内存的分配器。该分配器采用策略模式设计,支持灵活的分配策略插拔。在Master启动阶段,若检测到CXL启用配置,系统会先创建CxlAllocationStrategy分配策略,再调用initializeCxlAllocator接口完成CXL分配器的初始化。这一设计确保了CXL内存资源的全局可视与统一调度,提高了总体的内存利用率。
■标准API适配与功能打通
KOS团队完成了Put/Get、BatchPut/BatchGet等标准接口的CXL适配,使上层应用能够以完全透明的方式启用CXL存储KV Cache。这意味着,大模型用户可在Mooncake框架下以标准KV Cache API操作CXL内存,无需修改业务代码即可完成KV Cache的读写操作。
上述工作实现了两个层面的深度整合:架构上,将CXL纳入Mooncake统一的存储层级体系;资源调度上,通过全局分配器实现跨节点地址空间的统一管理。
从“可用”、“好用”到“智能” 三阶段演进全面铺开
这些创新设计,为Mooncake生态带来了三重核心价值:
架构层面:Mooncake框架首次原生支持CXL内存介质,通过内存语义访问与内存池化机制实现内存直连访问和多主机间内存共享,构建了面向未来AI负载的新型存储层级。
用户体验层面:大模型用户可在Mooncake框架下以标准KV Cache API操作CXL内存,完成KV Cache读写,在享受CXL低延迟、高带宽优势的同时,无需承担接口适配成本。
演进路径层面:针对大模型长上下文推理、高并发请求等内存敏感型场景,提供了基于CXL的内存扩展方案,并为后续DRAM-CXL-SSD多级存储体系奠定了坚实基础。
此次首阶段代码合入只是起点。未来几个月,KOS团队将遵循“可用-好用-智能”的技术演进路径,从三方面推进:首先完善CXL单级存储功能确保“可用”,继而构建DRAM-CXL-SSD分级体系实现“好用”,最终开发冷热数据智能升降级机制达成“智能”,以此加速CXL与Mooncake在以内存为中心的跨节点共享内存的原创突破。
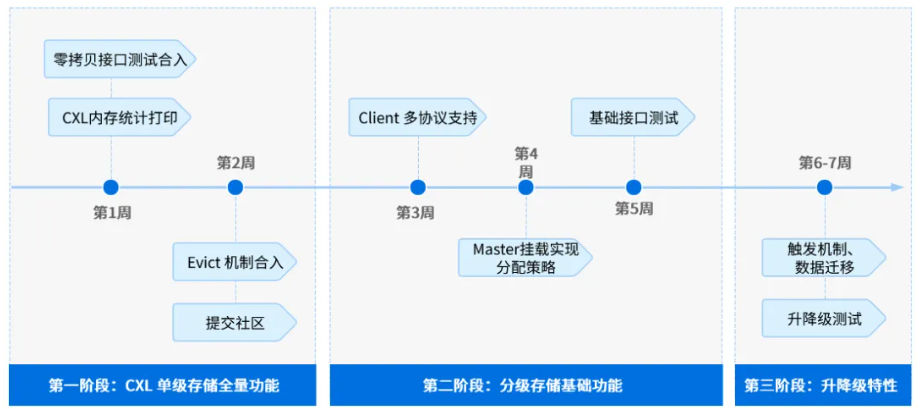
CXL功能合入路线图
浪潮信息与Mooncake社区围绕CXL+AI的合作,将为行业带来多方面收益:对Mooncake社区而言,这一贡献提供了基于CXL池化内存的全新存储层级,将CXL纳入KV Cache统一管理体系,显著延伸了推理上下文存储能力。社区开发者可直接复用该存储层级,无需自行实现复杂的底层内存管理,大幅降低CXL场景下KV Cache的适配成本。更重要的是,这为长上下文推理和跨节点KV Cache共享提供了可落地的实践路径。对AI Infra生态而言,此次贡献为大模型推理集群提供了一种无需RDMA网络、直接通过内存语义读写KV Cache的新路径。这一方案在特定场景下可显著降低网络硬件成本与复杂度,推动CXL在AI Infra领域的应用落地,为行业提供多元化的技术选择。
未来,浪潮信息将持续投入AI基础软件开源,将KOS内核优化能力反哺社区。在此,诚挚邀请更多开发者关注Mooncake项目,参与CXL生态建设,共同推动AI基础设施的技术革新。
本文技术细节基于浪潮信息向Mooncake社区提交的开源代码,相关PR已合入主分支。
🙋欢迎访问Mooncake GitHub仓库https://github.com/kvcache-ai/Mooncake了解详情!


售前咨询


售后服务

回到顶部
 售前咨询热线:400-860-6708
售前咨询热线:400-860-6708 售后服务热线:400-860-0011
售后服务热线:400-860-0011 7*24小时服务
7*24小时服务