在AI推理场景中,GPU长期处于高负载运行状态,而CPU虽然具备一定推理能力但却大部分闲置,整机算力未能得到充分释放,造成了算力资源的浪费与推理效率的结构性失衡。
针对这一问题,元脑服务器操作系统KOS(简称元脑KOS)创新推出面向AI推理场景的KeyACC异构推理加速器。该功能通过重构CPU与GPU的协同调度机制,使操作系统能够实时感知AI任务状态,并依据负载特征,动态选择最优执行路径,通过将GPU的部分推理请求整体或Decode阶段动态卸载至CPU,实现CPU与GPU的资源动态调度。实测显示,对比纯GPU推理方案,KeyACC可实现AI推理并发数提升72%、吞吐量提升44%,显著提升整机资源利用率与推理效率。

KeyACC异构推理加速器主视觉图
随着大模型推理的部署规模持续扩大,推理系统的优化重点正从单纯提升GPU性能,转向提升整机资源协同效率。尤其是在企业级推理场景中,业务请求波动明显、模型参数规模多样、并发需求持续提升,单纯依赖GPU承载全部推理任务,容易造成GPU侧长期拥塞、CPU侧算力资源闲置的结构性矛盾。
当前AI推理体系中,CPU与GPU分工高度固化,是导致资源利用不均的核心原因。一方面,深度学习框架长期围绕GPU进行优化,主流计算路径高度依赖GPU的软件生态;另一方面,容器编排与资源管理等调度系统普遍将GPU设定为AI任务的默认执行资源,而CPU主要承担数据处理与调度职责。这种从框架、编排再到操作系统的路径依赖,使CPU在系统层面难以参与推理任务执行。
即便新一代CPU硬件能力已经发生显著变化,在多核架构、向量计算、矩阵指令以及DDR5高带宽内存等方面能力持续增强,已能承载部分AI任务负载,但由于传统操作系统缺乏对AI任务计算特征的感知能力,无法对不同阶段进行精细化调度,导致CPU算力难以参与推理执行,形成“结构性闲置”。
为此,元脑KOS推出KeyACC异构推理加速器,重构操作系统对AI任务特征的感知与调度能力。KeyACC基于对推理负载的实时感知,提供全链路卸载与阶段卸载两种异构协同模式。前者在轻量模型(PD不分离)场景下,采用“阈值触发+队列缓冲”机制,将峰值时的推理请求整体卸载至CPU,负载回落后再平滑回迁至GPU;后者在高并发(PD分离)场景下,通过“阶段绑定+KV传递”机制,将访存密集的Decode阶段动态卸载至CPU,并借助共享内存实现KVCache零拷贝传输,支持弹性流水线调度。两种模式协同配合,实现对GPU负载的精细化调度与弹性削峰。
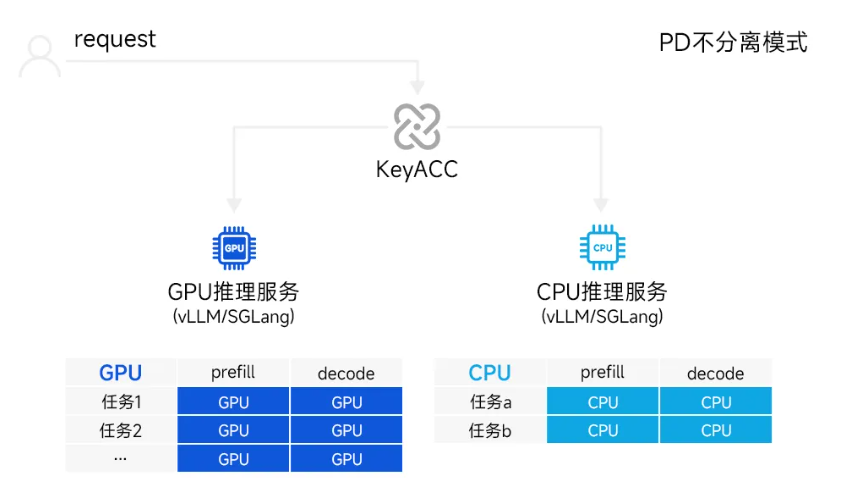
针对请求量较低、延迟不敏感的轻量模型场景,推理请求的预填充与解码在同一设备连续完成,即采用PD不分离架构。在此架构下,由于单次推理所需的算力与显存占用相对较小,CPU已具备独立承担端到端推理的能力。
全链路卸载CPU-GPU异构推理示意图
针对这一场景,KeyACC通过全链路卸载机制,实现推理任务在CPU与GPU之间的整体迁移,在业务无感的前提下完成动态削峰与资源均衡。其核心创新包括:
■ 无感调度:系统自动完成推理任务在CPU与GPU间的分配与绑定,业务层只需如常发送推理请求,无需感知任务实际运行在何种硬件上。
■ 队列缓冲防抖:系统实时监控CPU与GPU的双向队列深度,仅当某设备队列持续低于安全阈值(而非瞬时波动)时,才将新请求分配至该设备,确保调度平稳。
■ 显存安全回迁:在推理任务从CPU回迁GPU前,KeyACC预先校验GPU剩余显存容量,若显存不足任务将在CPU端等待直至资源释放,彻底杜绝因显存溢出导致的推理崩溃。
测试显示,以Qwen3-14B(FP16)为例,对比纯GPU推理方案,KeyACC全链路卸载机制可将AI模型推理并发数提升72%,吞吐量提升44%。
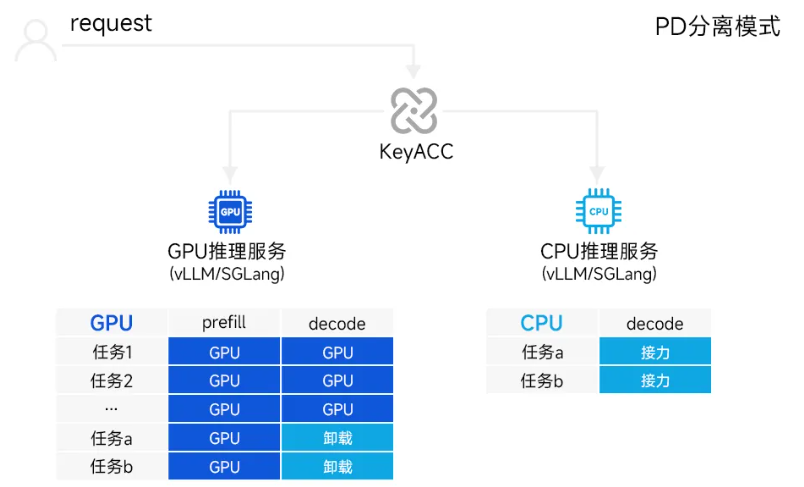
在高并发、长序列推理场景下,行业普遍采用PD分离架构,即Prefill与Decode阶段拆分执行。然而,传统PD分离更多只是完成了计算流程上的拆分,并未真正解决GPU持续承载Decode阶段的问题。尤其是在高并发场景中,Decode阶段对显存和带宽的占用依然较高。
阶段卸载CPU-GPU异构推理示意图
针对这一问题,KeyACC通过阶段卸载模式,将访存密集、适合异构分担的Decode阶段动态迁移至CPU侧执行,发挥CPU在内存带宽和多路并行上的优势,实现更精细的异构协同调度。其核心能力包括:
■ 异构数据无缝衔接:通过共享内存实现KVCache零拷贝传输,提升跨端数据交换效率;同时预置reshape策略自动适配GPU与CPU张量布局差异,确保CPU加载数据时格式匹配,避免解码乱码。
■ NUMA感知并行解码:引入NUMA感知机制,将KVCache按节点切分并映射至本地内存,实现多CPU socket并行Decode,聚合内存带宽与计算核心,突破单节点瓶颈,显著提升吞吐。
■ 弹性流水线动态调度:以固定token为周期动态决策任务流转,Prefill在GPU执行,Decode迁移至CPU;每生成指定token数即检查GPU负载,资源释放后自动回迁,实现流水线并行与负载平衡。
测试显示,以DeepSeek-R1-70B(FP16)为例,对比纯GPU推理方案,KeyACC阶段卸载模式可将并发数提升68%,吞吐量提升40%。
综上,元脑KOS KeyACC通过对AI任务特征的深度感知与异构算力的精细调度,打破了“AI推理只能由GPU承担”的传统模式,在轻量负载与高并发场景下,KeyACC均能突破单卡物理限制,将推理并发大幅提升,实现整机异构资源的系统级释放。


售前咨询


售后服务

回到顶部
 售前咨询热线:400-860-6708
售前咨询热线:400-860-6708 售后服务热线:400-860-0011
售后服务热线:400-860-0011 7*24小时服务
7*24小时服务