随着AI训练与推理规模持续攀升、Agent软件基础设施加速落地,智算中心服务器正从传统单芯片形态向多芯粒(Chiplet)架构快速演进。以业界主流的新一代多芯粒架构为代表的服务器CPU,将多个芯粒封装在同一颗处理器内。这种架构在提升核心密度的同时,也带来了一个被长期忽视的问题——操作系统调度器对芯粒拓扑结构“视而不见”。
为攻克调度性能瓶颈,元脑服务器操作系统KOS推出Chiplet拓扑感知调度器 TopoSched,通过 eBPF 架构实现定制化、可扩展的线程调度能力,结合用户态全局资源分配策略,实现面向Chiplet架构的细粒度调度控制。实测显示,对比系统原生调度器,在iperf基准测试中,TopoSched可实现1.57 倍的吞吐量提升;共享内存测试中,TopoSched可实现73.6%的性能提升;redis场景下可实现38.5%的性能提升。
Chiplet设计理念是将传统单颗SoC拆解为多个功能裸片,通过先进封装互联集成。以典型的多chiplet处理器为例,单颗CPU封装内包含多个 compute DIE,这些compute DIE通过高速互联技术相连。每个compute DIE中所有的核心共享同一个LLC缓存。
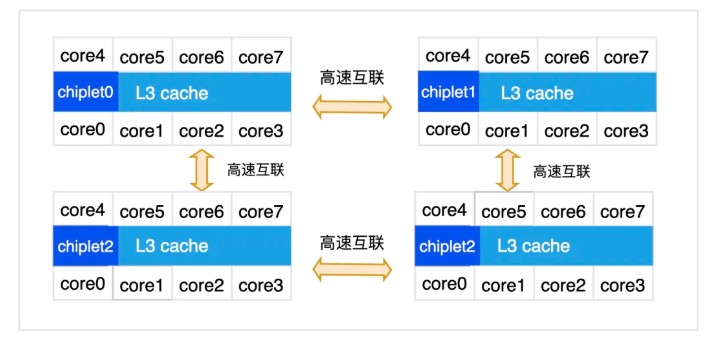
chpilet架构CPU拓扑图
然而,Linux内核默认调度器对拓扑结构的感知停留在NUMA层面。在调度决策时,它会尽量将任务保持在同一NUMA节点内运行,但对NUMA节点内部的芯粒/LLC边界则缺乏精细化的感知能力。具体表现为三个层面的问题:
■任务漂移问题:同一线程在不同调度周期中可能被分配到不同芯粒上执行,导致LLC缓存频繁失效。每次跨芯粒漂移都意味着需要跨CCD通信。
■资源分配粗粒度问题:内核默认以单个任务为单位进行公平调度,无法将一组相关联的任务(如同一虚拟机的所有vCPU或同一容器内的业务线程)作为一个整体,优先调度到同一芯粒上运行。
■负载均衡与局部性的矛盾:内核的负载均衡机制为了维持CPU间的负载均衡,会主动将任务从繁忙的CPU迁移到空闲CPU上,这种迁移完全不考虑目标CPU是否与原CPU位于同一芯粒,可能反而增加了跨芯粒访存开销。
针对传统调度器不能识别与理解Chiplet 架构下LLC缓存物理边界,无法充分发挥服务器Chiplet架构性能优势的问题。元脑服务器操作系统KOS推出Chiplet拓扑感知调度器 TopoSched,通过用户态芯粒拓扑感知、基于LLC的资源分配算法、动态调度技术实现面向Chiplet架构的细粒度调度控制。
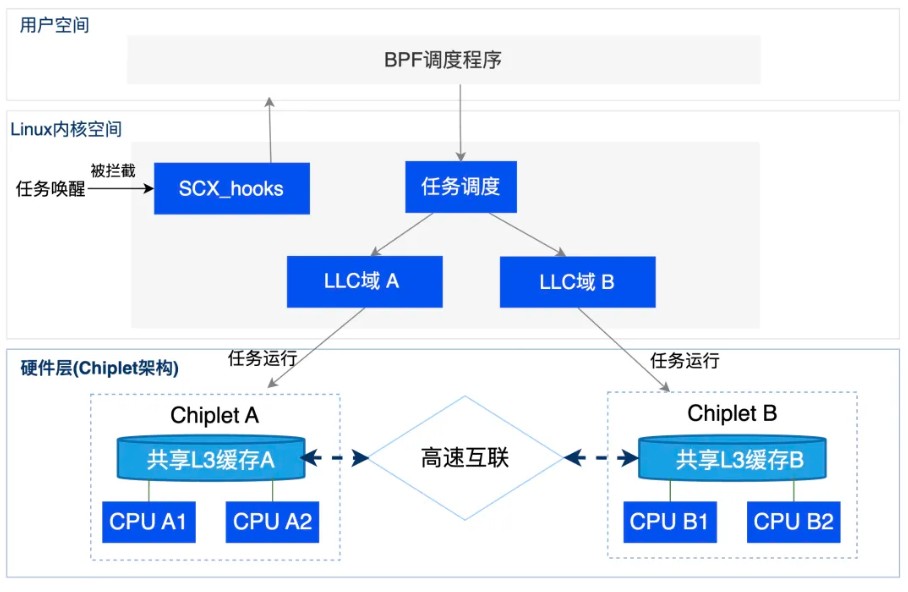
TopoSched 调度方案
■ 芯粒拓扑感知:调度器原生支持拓扑感知,可识别NUMA节点、LLC缓存、CPU Core和逻辑CPU,并建立完整的拓扑视图。
■基于LLC的资源分配算法:确定每个业务应分配多少个CPU以及这些CPU应落在哪些拓扑位置,将任务划分为线程组,优先以芯粒为单位进行线程组的CPU资源分配。同时业务运行过程中实时统计负载数据信息,并在下一轮调度周期重新计算。
■ 动态调度技术:摒弃传统的硬绑核策略,支持CPU资源的动态调度,在低负载状态下,优先使用芯粒亲和范围内的算力资源,最大限度减少跨芯粒通信延迟;当负载偏高时则溢出当前任务偏好的CCD,动态扩容算力资源,拓宽业务运行算力调度范围,避免算力资源抢占。
■ iperf基准测试
我们搭建四组虚拟机开展iPerf 网络性能测试,为排除测试波动干扰设置四组对照实验,对比验证系统默认调度、NUMA 绑定与 TopoSched 调度方案的吞吐量表现。测试结果表明,NUMA 绑定与 TopoSched 方案运行性能更为平稳,系统默认调度结果波动明显,原因是默认调度允许进程跨Socket 调度,性能受Socket通信频次影响较大。总体来看,TopoSched 相较系统默认调度最高性能提升1.57 倍,较 NUMA 绑定方案性能提升 85.4%,核心优势在于该调度机制可将业务线程优先收敛至同一芯粒运行,大幅减少跨芯粒数据通信开销。
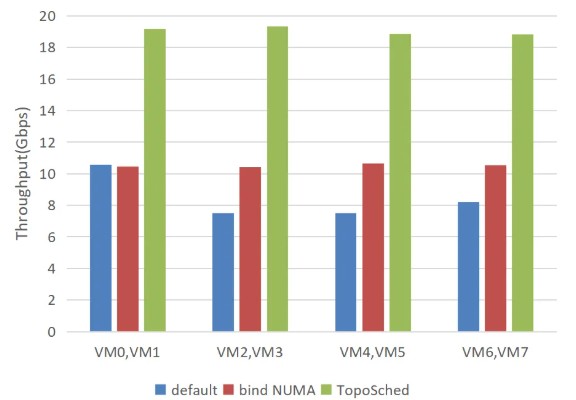
iperf基准测试,结果越大越好
■ 进程间共享内存测试:
我们设置四组对照实验,对比验证系统默认调度、NUMA 绑定与 TopoSched 调度方案在进程间共享内存的性能表现(每次读写4KB数据,连续读写1亿次)。测试结果表明,对于单次读写耗时,TopoSched 相较系统默认调度读写延时降低最高73.6%,较 NUMA 绑定方案延时降低 60.8%。
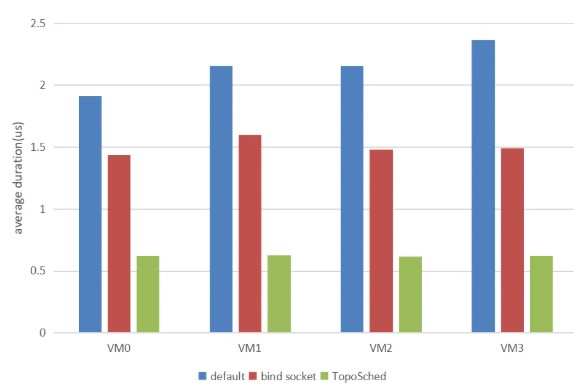
进程间共享内存单次读写耗时性能,越小越好
■ redis场景测试
我们搭建四组虚拟机开展redis性能测试(set写、get读),为排除测试波动干扰设置四组对照实验,对比验证系统默认调度、NUMA 绑定与 TopoSched 调度方案的吞吐量表现。测试结果表明,TopoSched 相较系统默认调度的写请求QPS最高提升38.5%,较 NUMA 绑定方案性能提升 34.6%。
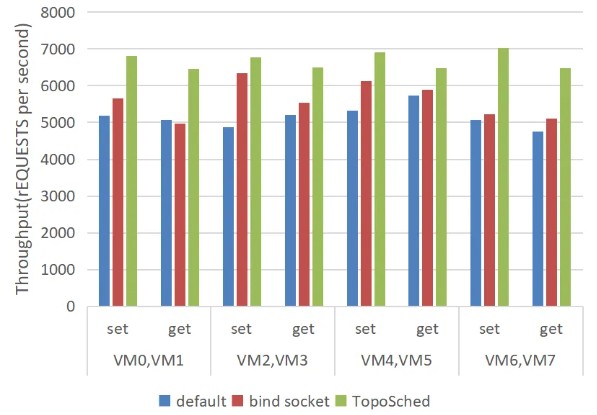
Redis 性能测试,数值越大越好
随着Agentic AI 时代到来,CPU 已从传统辅助算力升级为核心任务调度中枢,统筹承载工具调用、API 请求、向量检索等各类业务流程。面向Chiplet 架构CPU优化设计的 TopoSched 调度方案,也能够深度适配Agentic业务场景,充分发挥Chiplet 架构的优势。


售前咨询


售后服务

回到顶部
 售前咨询热线:400-860-6708
售前咨询热线:400-860-6708 售后服务热线:400-860-0011
售后服务热线:400-860-0011 7*24小时服务
7*24小时服务