元脑服务器KOS推出DeepSeek定制优化版操作系统
2025-06-17
今年以来,DeepSeek成为许多行业大模型部署的首选。然而,在实际应用DeepSeek过程中,企业面临着诸多挑战,例如复杂的部署流程增加了实施难度,有限的资源限制了模型的运行效率,数据安全与隐私保护问题更是亟待解决。
为此,元脑服务器操作系统KeyarchOS(简称KOS)推出了DeepSeek定制优化版,利用一键部署工具集,实现DeepSeek推理服务分钟级高效部署;通过深度软硬协同,同等配置情况下,CPU与GPU推理场景中,单用户调用tokens/s 提升37%,GPU利用率从30%提升到近40%,DeepSeek-R1 671B模型的加载时长从1小时缩短到3-5分钟,纯CPU推理场景下,将单用户调用tokens/s提升超过10%;此外,定制优化版还构建了以机密计算、可信计算与eBPF为核心的安全防护机制,有效保障了训练与推理过程中的数据隐私与模型安全。

企业应用DeepSeek面临部署复杂、性能瓶颈、数据安全等难题
自DeepSeek问世以来,企业纷纷利用其先进技术架构与算法来开发、优化自身业务,以期提供更优质的产品与服务。然而,在DeepSeek实际应用过程中,企业往往面临着部署复杂、性能瓶颈与数据安全等方面的问题。
■ 首先,DeepSeek的适配与部署过程相对复杂,企业需要投入大量时间与技术资源进行从模型选择到环境配置的全流程优化。DeepSeek的技术架构对软硬件环境要求较高,企业需要在不同平台与框架之间进行复杂的适配工作。例如,根据实际业务需求,企业需要对模型的输入输出接口、数据格式以及运行环境进行定制化调整;此外,DeepSeek本地部署还涉及多种技术栈的协同,包括Python环境配置、依赖库安装以及模型加载,这些复杂的适配与部署工作不仅增加了开发成本,还延缓了业务上线的速度。
■ 其次,企业在使用DeepSeek进行推理时,往往难以充分释放硬件性能,导致时间、人力与资金的浪费。在实际应用DeepSeek过程中,CPU与GPU的利用率十分有限,需要专业的软硬件人员花费大量时间进行协同优化。例如,在使用某双路服务器进行CPU+GPU混合算力推理时,GPU利用率仅为30%,单用户调用的解码速度较低,难以满足生产级应用需求。对于1TB模型(DeepSeek-R1 671B Q4量化版),磁盘加载时长超过3小时,即使切换为SSD,其加载时长仍需40分钟以上。这些因素制约了企业使用DeepSeek的效率与成本效益,亟需更高效的方案来打破性能瓶颈。
■ 最后,企业使用DeepSeek时面临敏感信息泄露风险、多租户数据隔离难题与多模态数据管理复杂性,亟需保障数据隐私性与完整性。随着DeepSeek在智能客服、金融分析、内容创作等领域的广泛应用,企业需要处理大量敏感信息,如客户咨询记录、金融交易数据与个人隐私信息等,这些数据在存储、传输与处理过程中存在泄露风险。此外,DeepSeek支持多模态输入与跨模态任务处理,这使得数据来源更加复杂,数据安全管理难度增大。
KOS DeepSeek定制优化版实现快速部署、性能释放及全面防护
对于以上问题,KOS推出DeepSeek定制优化版,凭借便捷的一键式部署工具、深入的软硬协同调优以及全面的安全防护体系,助力企业高效接入DeepSeek推理服务。
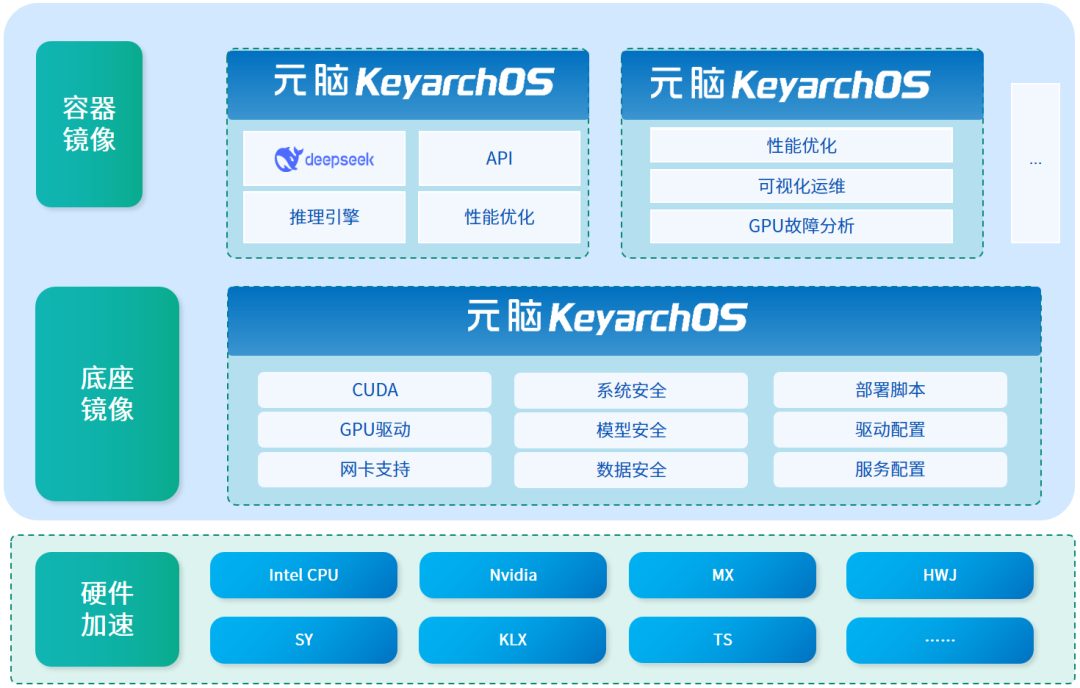 KOS DeepSeek定制优化版架构图
KOS DeepSeek定制优化版架构图
首先,DeepSeek定制优化版提供了配套的一键部署工具集,实现DeepSeek分钟级上线。在某大型项目中,KOS团队实现了20分钟内成功上线200节点大模型训练环境,基于该项目经验,KOS团队通过优化镜像构建与部署流程,解决DeepSeek部署过程中的硬件兼容适配、复杂依赖关系、驱动编译安装等问题,并将DeepSeek部署应用所需系统环境、依赖项、驱动及中间件等打包整合,开发了针对DeepSeek定制优化版的一键部署工具集。用户可通过PXE方式完成KOS的自动化安装,在系统安装的同时完成DeepSeek的一键部署、开箱即用。
其次,DeepSeek定制优化版专注于模型推理与软硬协同两方面优化,多技术协同实现硬件性能极致释放。在推理优化方面,面向CPU-GPU异构环境,DeepSeek定制优化版通过动态调度与自适应批处理实现计算资源高效调配,结合工作负载智能划分与任务卸载机制平衡系统负载,多技术协同提升GPU利用率及DeepSeek推理性能。在软硬协同方面,DeepSeek定制优化版通过NUMA技术优化内存访问路径,减少了内存延迟,提高了多核处理器的效率;采用内存大页技术减少页表项的数量,降低了内存管理的开销,进一步提升内存访问速度;利用CXL内存拓宽技术为系统提供更高效的内存空间,使得大规模数据处理更加高效。
通过上述两方面工作,DeepSeek定制优化版对底层硬件性能进行了极致压榨。在纯CPU推理时,DeepSeek定制优化版能够利用处理器SNC架构特性降低推理过程中的内存访问延迟,并通过优化内存分配算法充分利用DRAM与CXL内存带宽,将单用户调用tokens/s提升超10%。在CPU与GPU混合推理时,DeepSeek定制优化版也能显著提升推理效率,与业界同类产品相比,DeepSeek定制优化版将单用户调用的tokens/s提升了超过37%,GPU利用率提高10%,能够有效满足生产级应用需求。在推理服务升级、配置优化生效等生产场景下,DeepSeek-R1 671B模型的加载时长从将近1小时缩短至3-5分钟,这大幅减少了DeepSeek在推理过程中的中断间隔,提高推理服务的可用性,从而增强企业上层AI业务应用的用户体验。
最后,DeepSeek定制优化版将可信计算、eBPF安全及机密计算“三驾马车”融为一体,构建可信的DeepSeek全栈运行环境。DeepSeek定制优化版采用机密计算与加密技术,对DeepSeek训练与推理过程涉及的敏感数据进行精准加密,降低数据泄露风险。同时, 通过eBPF技术提供了低开销、内核零侵入的安全监控与访问控制能力,支持灵活的访问控制策略,能够根据DeepSeek的多模态输入与跨模态任务处理需求对安全策略进行定制,降低数据安全管理的复杂性。
KOS DeepSeek定制优化版凭借一键部署工具集、软硬协同调优技术及“三驾马车”安全防护体系,显著提升了DeepSeek的部署效率与应用性能,并为数据隐私与模型安全提供了可靠的保障,为行业采用DeepSeek开展业务创新与智能化转型提供了有力支持。

 第七代服务器
第七代服务器













 访问 AIStore
访问 AIStore