AIGC推动了各行业的创新与变革,同时也对智算中心算力系统的资源调度和通信互联提出更高的要求。随着算力需求的持续增长,智算中心网络设备部署与运维的复杂性迅速攀升,如何全面、精细、智能地管理网络,对提升AI性能,保障AI业务连续性至关重要。
面对智算中心的网络管控需求,浪潮信息智能运管平台ICE全面升级,通过端到端统一管理、高精度实时监控及智能故障分析预警,将智算中心的网络部署周期从周缩短至天,AI训推场景下网络核心关键数据的监控时间降低至微秒级,整体运维效率提升超过50%,大幅提升AI网络的通信效率、可靠性和灵活性,加速AI业务的创新落地。
AIGC场景下网络管理面临3大挑战
随着知识问答、文生图、多模态等AI模型的加速发展,智算中心需要满足AI大模型的大规模并行计算、高吞吐量数据传输及低延迟响应等更高要求,由此带来网络管理运营复杂、精细化监控及高可靠性要求等全新挑战:
■ 自动化程度低,智算中心网络运维管理效率低:随着智算中心算力规模的快速增长,大规模AI计算组网让网络设备数量大幅增长,网络运维管理涉及海量参数配置、拓扑结构设计和性能调优等,人工运维管理复杂。例如,在AI大模型训练过程中,不同节点间GPU要进行不定期的数据同步,产生突发的大象流(如All Reduce和All to All),为确保网络的无阻塞传输,上下层的网络拓扑收敛比从传统的1:3降低至1:1,网络设备间的连接呈几何级增长,面对海量设备的数千条连接,人工查验核对可能需要数周时间。此外,在AI模型训练和推理不同场景下,由于模型不同,数据流和流量模型存在差异,需要更加自动化和智能化的网络性能调优策略。
■ 监控手段滞后,智算中心网络性能瓶颈难感知:在AI大模型训练过程中,跨节点的瞬时大象流数据会达到上百甚至上万GB,带宽利用率达到97.5%。这类瞬间突发的业务流量变化需要更高精度的实时监控来捕捉训练过程中的网络波动。但传统数据中心的业务流量传输过程中流量均衡,所以一般的网络监控很难适应AI业务流量中的微秒级波动变化,缺乏有效的端到端链路可视化工具监控丢包等实时细节,导致无法精准定位智算中心网络性能瓶颈点,影响GPU加速卡的高效利用和AI训练的效率。
■ 网络可靠性不足,AI业务连续性难保障:AIGC应用通常作为关键业务运行,对网络的高可用性和容错能力也提出了严格要求。据业界公开数据显示,随着智算中心规模不断扩展,可靠性问题愈发突出,万卡规模下算力系统瓶颈每3小时发生一次故障,其中10%是由网络异常引发。如果定位故障点和排查原因耗时过长,将极大影响业务的连续性,且由网络引发的故障可能对大规模实时业务产生更广泛的影响。
浪潮信息智能运管平台ICE,助力智算中心网络“全面、精细、智能”管控
针对AIGC时代下的智算中心网络运维管理难题,浪潮信息全面升级智能运管平台ICE。依托领先的技术架构和全新的智能技术,ICE能够实现网络基础设施的端到端统一管理、高精度实时监控及智能故障分析预警,为智算中心打造“全面、精细、智能”的新一代网络智能运管平台。
■ 超大规模网络部署周期从周缩短至天
智能运管平台ICE具备智能网络配置能力 ,能够实现网络的自动化管理,大幅减少了对人工干预的依赖,有效降低运营成本。其统一纳管平台结合自动化运维功能,显著简化了复杂网络环境的管理流程,提升超大规模网络配置优化速度,部署周期从周缩短至天,运维效率提升超过50%。
端到端统一管理:支持南北向标准协议,支持第三方工具与自定义应用开发,支持交换机、服务器、网卡、GPU的统一纳管,实现主机侧、网络侧的统一管理。
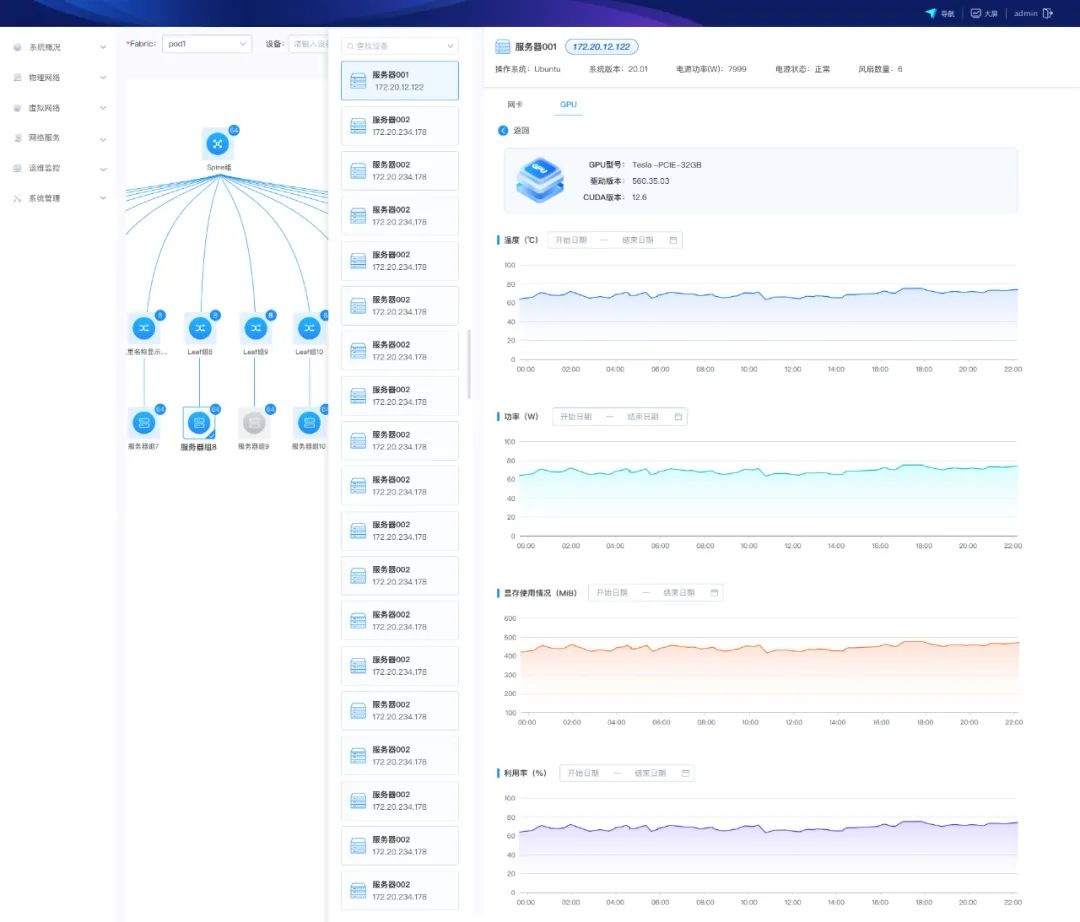 <CPU、网卡、GPU监控>
<CPU、网卡、GPU监控>
网络拓扑图形化规划:智算中心的网络拓扑结构复杂,纯手动配置时间长且容易出现错误。ICE智能运管平台可基于数字孪生技术构建AI网络拓扑实时仿真平台,为手动配置提供图形化界面,实时验证网络虚拟拓扑与实际设备端口拓扑连接情况,降低错配影响,提高网络部署效率,优化资源分配。
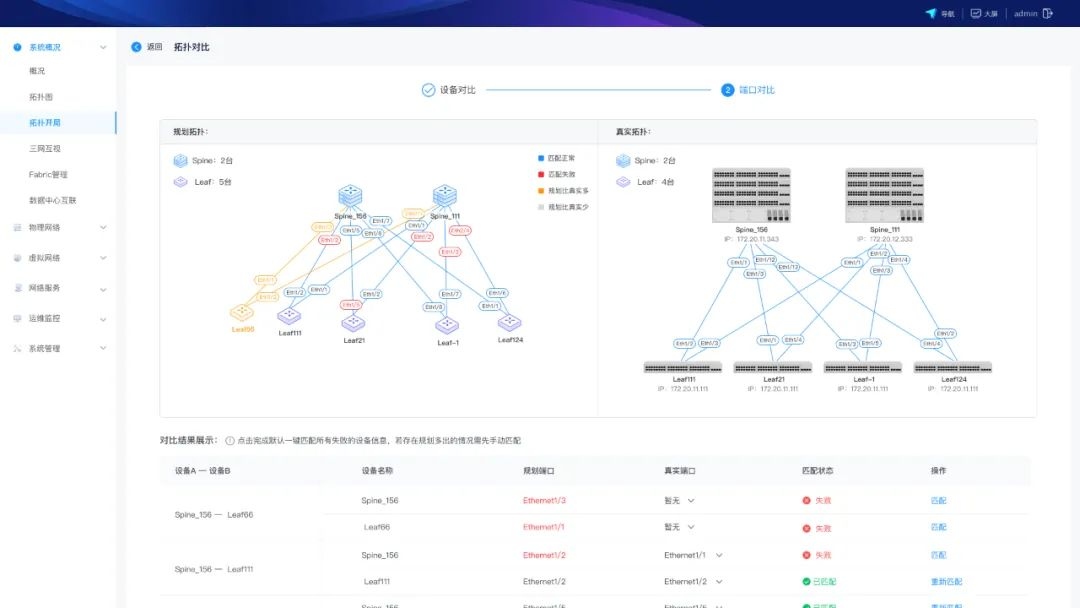 在线仿真平台
在线仿真平台
动态网络拓扑自动生成:实时反映智算中心网络健康状态、性能情况与连接关系。
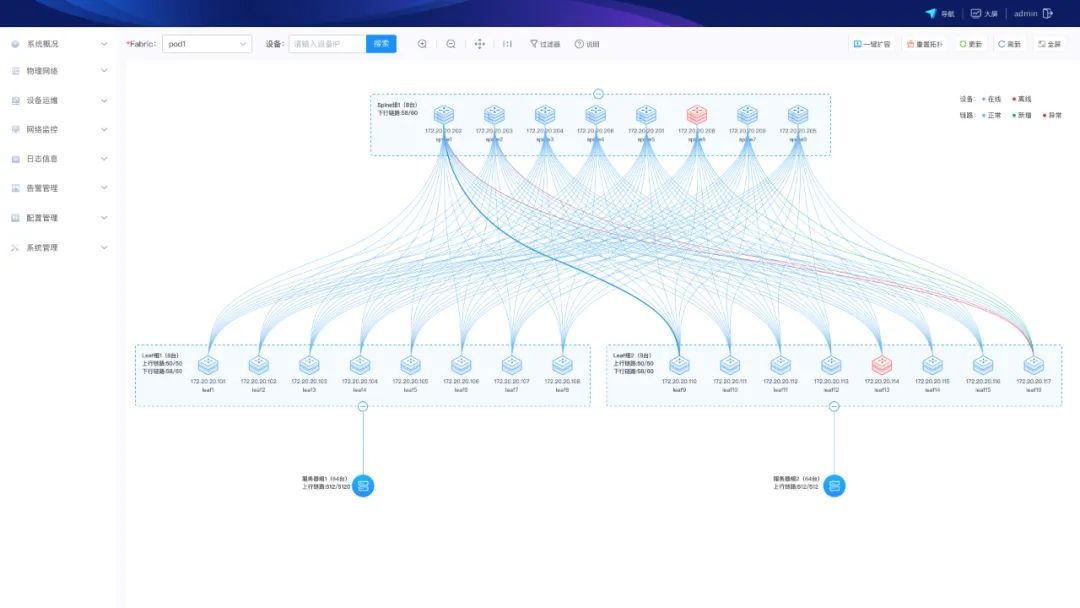 自动化网络拓扑
自动化网络拓扑
■ 精细化掌控网络状态,大幅提升智算中心网络性能
ICE为智算中心提供网络拓扑可视化、实时流量监控和负载智能调度功能,助力企业精准掌握网络状态,风险快速识别和故障问题定位,及时解决网络性能瓶颈;针对大模型节点间大象流的同步突发特征,还能改善网络流量的负载均衡问题,全面优化流量的路径分布,降低传输延迟,提升AI业务创新与应用的效率和计算资源利用率。
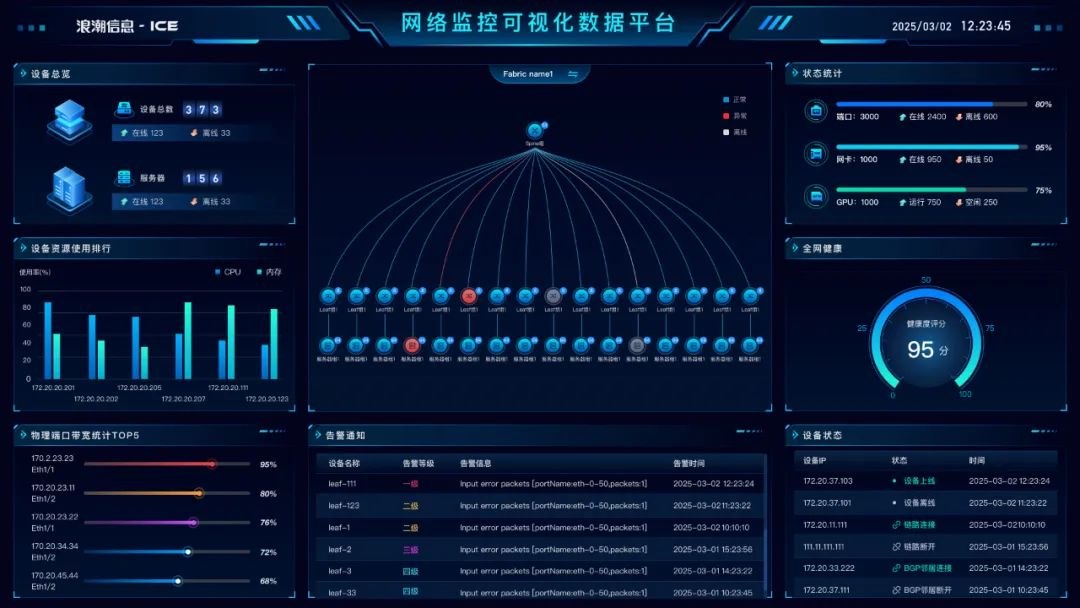 可视化大屏
可视化大屏
一键NCCL压力测试:在AI大模型训练前,平台可借助AI工具和训练模型构建网络信息数据库,对智算中心网络性能进行多维度检测,提高仿真AI网络压测准确性,为用户提供精准、可靠的训前压测画像,通过分析GPU、网络带宽利用率与平均时延是否达到训练的最佳配置状态,解决潜在的弱节点风险,确保算力发挥最大效率。
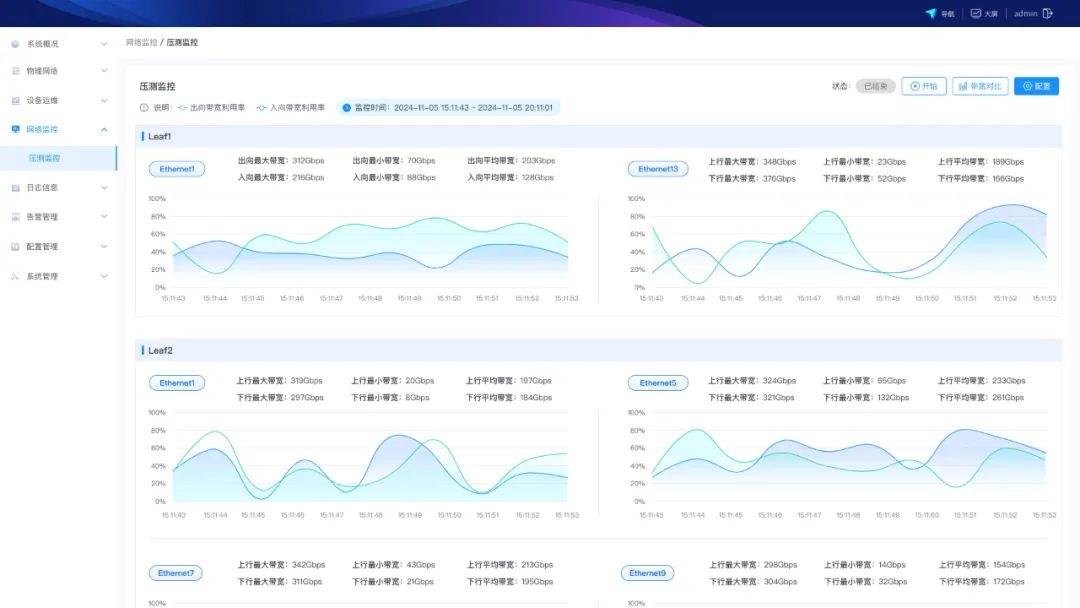
端到端信息采集:基于交换机和Host上的Agent,实时获取网络设备、链路、流量等多维度的信息,为用户提供实时的AI网络状态。
微秒级网络监控:AI大模型训推过程中,高精度Telemetry遥测技术能够实现微秒级的数据采集与监控,提供传统秒级监控所无法实现的详细网络行为视图,帮助用户快速、精准提升智算中心的网络性能。
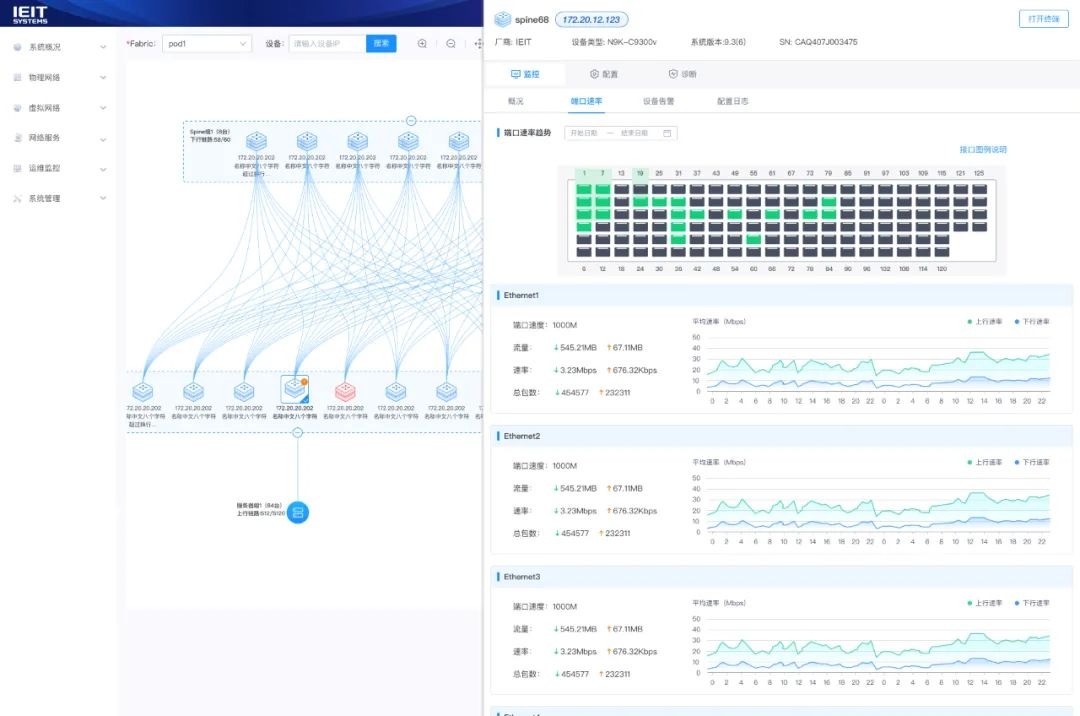
自定义可视化仪表盘:用户可多维度自定义网络监控仪表盘,实现对RoCE流量、带宽负载、延迟、丢包、拥塞等AI训练和推理过程中的核心关键指标进行个性化监控管理。
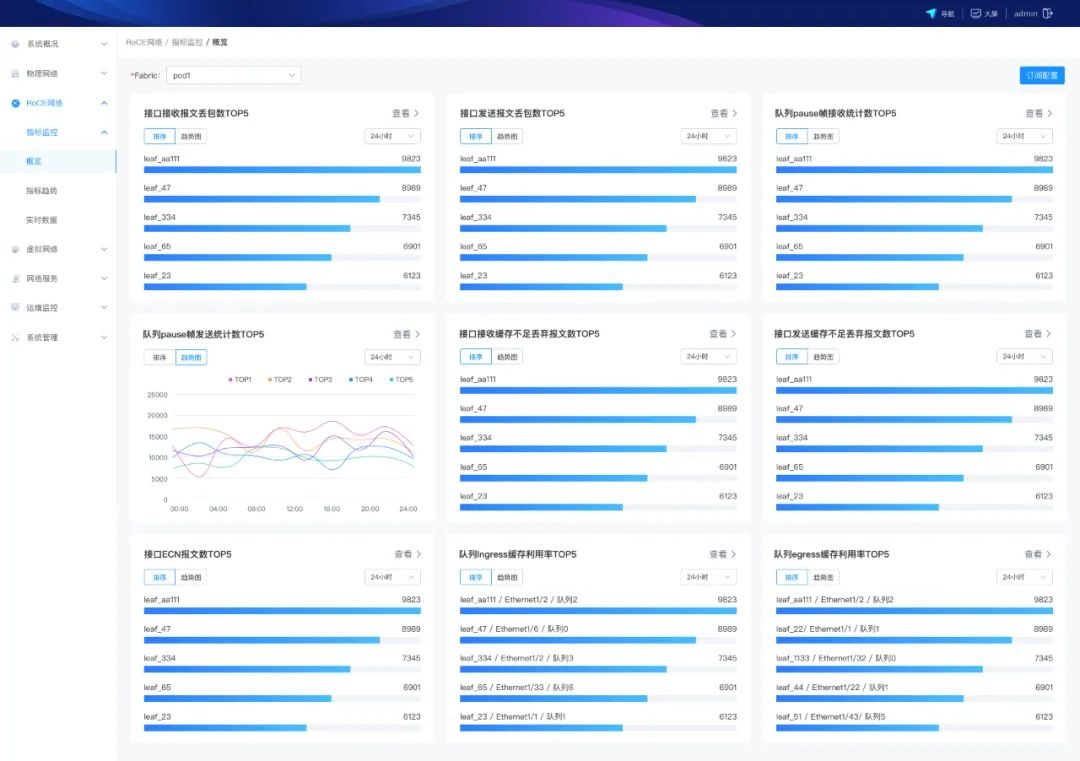 可视化仪表盘
可视化仪表盘
■ 智能检测预警,保障AI业务连续性
在AI大模型训练任务周期中,维持网络的稳定高效是极其重要的目标,ICE内置网络故障分析AI大模型,具备智能故障检测和自动修复能力,通过多路径冗余、自愈网络等技术手段,确保网络在故障发生时能够迅速恢复,显著提升了网络的可靠性和容错能力,减少业务中断时间。即使在高负载和复杂环境下,网络依然能够保持稳定运行,确保每个AI加速卡都能得到充分利用,保障企业的业务连续性,提升整体竞争力。
智能故障分析与定位:ICE支持网络故障智能分析,基于带内Telemetry遥测、sFlow 和 NetFlow 技术分析流量缓存,能够重现故障链路状态,并实现分钟级故障智能追溯、异常流量识别与潜在风险预警,保障网络稳定。
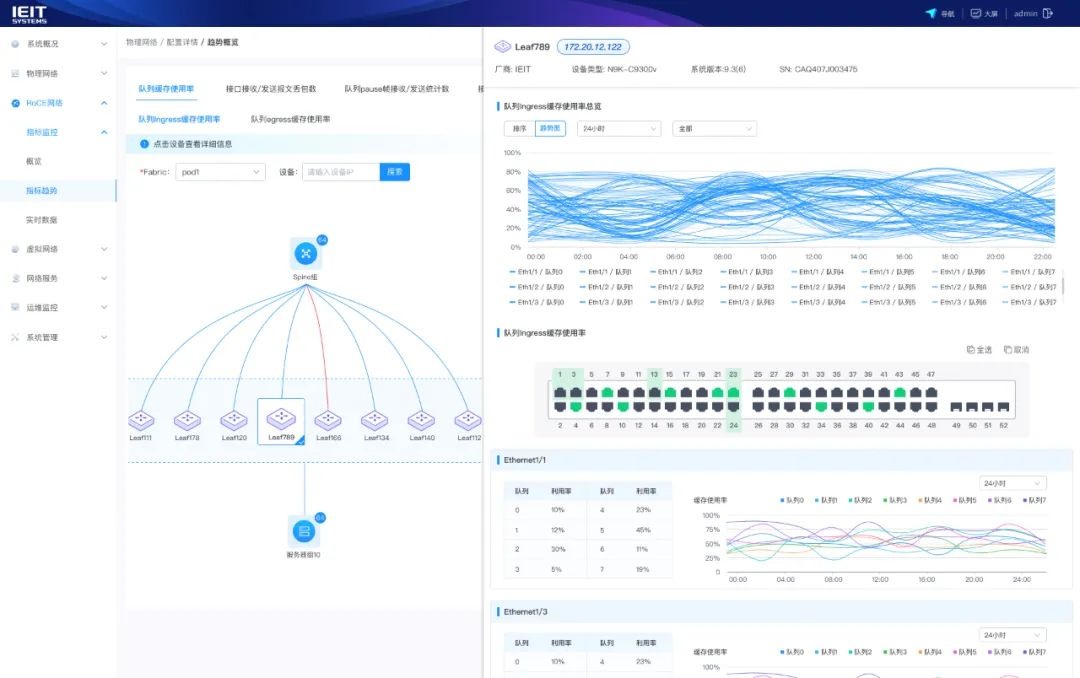
光模块故障精准预警:ICE平台通过精准捕捉光模块的细微变化,基于领先的AI算法,能够提前预判故障风险,将传统的事后被动更换转变为提前主动预防。
在AIGC时代,网络管控已不再是传统的设备配置与监控,而是面向未来的智能化、自动化以及可视化的平台。ICE平台正是这一趋势下的先行者,通过简化智算中心的网络管控,提升管理效率与故障响应速度,大幅提升智算中心网络性能和稳定性,为AIGC时代的网络基础设施带来全新的变革与升级,显著加速AI模型的迭代和业务创新进程。

 第七代服务器
第七代服务器














 访问 AIStore
访问 AIStore