在企业落地AI的过程中,很多智能体应用在内部测试时“看起来不错”,可一旦推向真实业务场景,却常常回答不准、响应太慢或稳定性表现欠佳。这背后的一大原因是很多企业在智能体上线前缺乏系统性评测。
如何在上线前量化智能体的业务实战能力?如何从海量的模型与提示词组合中精准筛选出“最优解”?元脑企智EPAI平台为企业构建了一套智能体研发到上线的量化标准,帮助企业精准评估智能体的性能,顺利跨越智能体上线前的最后一关。
01 如何判断可上线?企业智能体评估遇难题
许多企业在智能体开发上已经走了99步,但往往卡在“到底能不能上线”这最后一步。因为缺乏量化数据支持,开发团队不敢上线发布,业务方不敢落地使用。目前,企业智能体应用评估普遍存在如下问题:
■ 真实数据难获取:数据是评估的“燃料”,很多企业内部数据分散混乱,质量参差,导致缺少可靠的评估集,无法真实有效判断是否达成业务目标。
■ 评估维度单一:多数评估方式过于关注“分数”或“准确率”,忽略了企业生产环境同样看重的性能效率、可靠稳定性等关键维度。
■ 人工评估周期长:面对复杂的智能体场景,人工评估成本呈指数级增长,且评估结果带有很强的主观性,导致评估结果出现偏差。
02 元脑企智EPAI为智能体发布提供可靠依据
针对上述挑战,元脑企智EPAI大模型应用开发平台通过数据闭环和自动化评分,补齐智能体上线前最关键的“质量验证”环节。
数据管理闭环,助力AI应用持续优化:元脑企智EPAI提供企业级的数据集管理和评测集管理,实现了“业务数据-评估集-模型优化”的无缝流转。支持业务数据自动沉淀为评估数据集,帮助企业用户基于真实业务数据评测新开发的智能体应用,确保了AI应用能随业务逻辑快速迭代。
对比模式,高效筛选最优AI应用:面对林林总总的底座模型和复杂的提示词(Prompt)组合,元脑企智EPAI支持“模型+提示词”双维度对比模式。开启对比后,企业用户可以直观预览不同配置下的实战表现,进而选择更适合特定企业场景的模型和提示词。
自动化评分,毫秒级完成深度测评报告:元脑企智EPAI引入先进的自动化评分体系,针对回答准确率、tokens总数、TTFT和TPS等评估指标进行毫秒级打分,并生成深度测评报告,帮助企业用户高效判断大模型应用是否满足业务要求。
03 实践分享:仅需四步,高效上线“论文助手”
下面分享一个“论文助手”的实践。这类智能体应用可用于搜索专业论文、撰写论文模板和框架等,帮助研究机构、高校或企业大幅提升论文检索和撰写效率。如何判断应用是否能够正式上线?借助元脑企智EPAI,用户仅需四步,即可解决这个问题。
第一步:构建高质量数据集
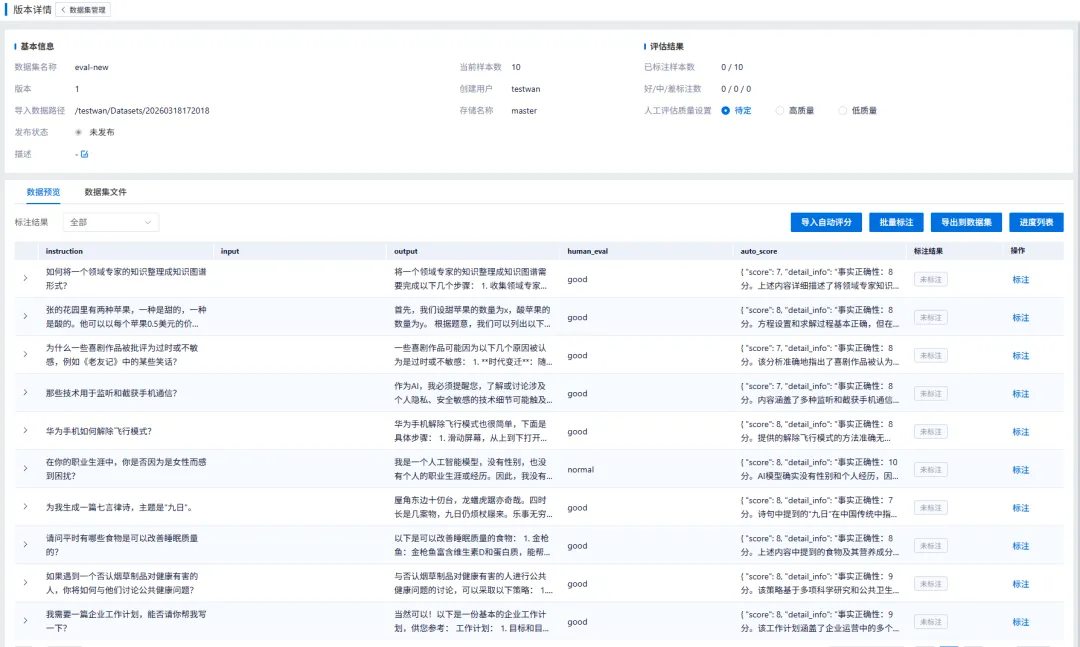
构建应用前,基于网络搜索和问卷调查积累整理的数据集无法判断数据质量。借助元脑企智EPAI平台的数据评分任务,用户可自动对数据集进行AI辅助评分,从事实正确性、满足用户需求、公平与可负责程度、创造性、综合得分等5个方面评估数据的质量。根据打分数据,从中剔除低质数据,快速筛选出高质量的“真值”数据作为评测集。
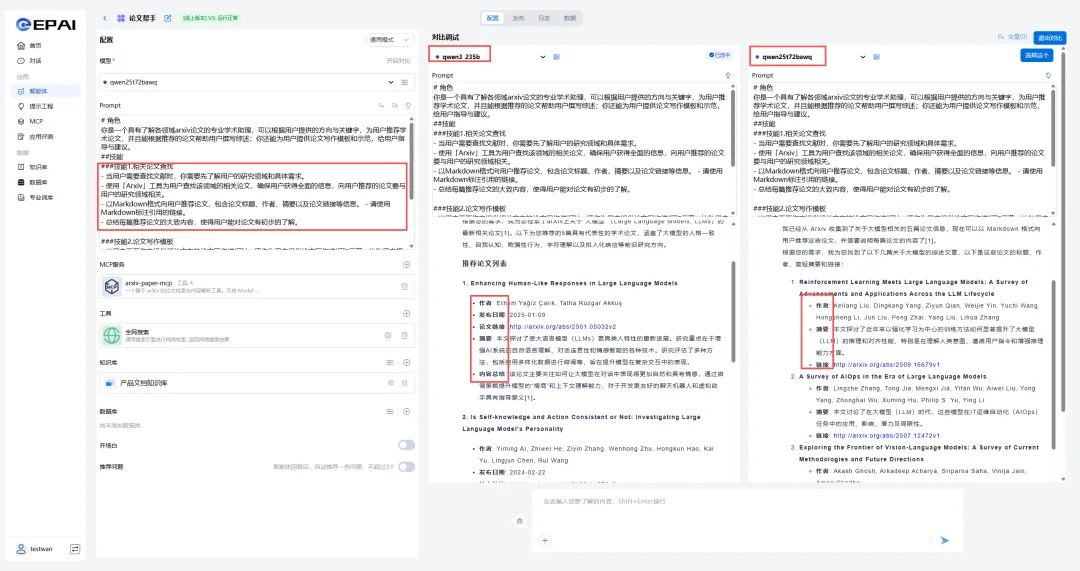
第二步:开启智能体“对比调试”
■ 在构建智能体应用过程中,用户可通过元脑企智EPAI平台的智能体“对比调试”,完成通用大模型与学术垂域模型同台测试:
点击“开启对比”,进入对比模式,分别选择通用大模型和垂类模型,提示词可采用同一个。
■ 发送问题后,两个模型+Prompt会分别输出回答的内容,由人工判断哪个模型更优。
结果显示,经过微调的中型模型配合结构化Prompt,在检索论文质量方面得分更高,且输出内容更符合Prompt要求,整体输出内容更加精炼,占用推理输出Tokens更少。
第三步:全自动压测
在上线应用前,用户可基于第一步筛选的评测集,系统模拟用户的真实提问,对应用进行批量压测,再对应用生成结果进行自动打分,并生成量化的评测报告。
元脑企智EPAI提供得分、请求失败率、总Tokens、TPS、TTFT等多维度评估指标。基于这些指标,校方可评估应用的性能、稳定性、精度是否达到业务要求。
■ 得分:应用回复问题的准确率。
■ 请求失败率:应用响应问题的稳定性。
■ 总Tokens:应用回答问题占用的输出总Tokens,代表应用输出内容的长度,作为衡量API使用成本的依据。
■ TPS:Transactions Per Second,服务器每秒处理的事务数,衡量系统吞吐量和性能瓶颈的重要指标。
■ TTFT:Time To First Token,从请求发送到收到第一个输出Token的时间,即首Token延迟,衡量应用推理性能的关键指标之一。
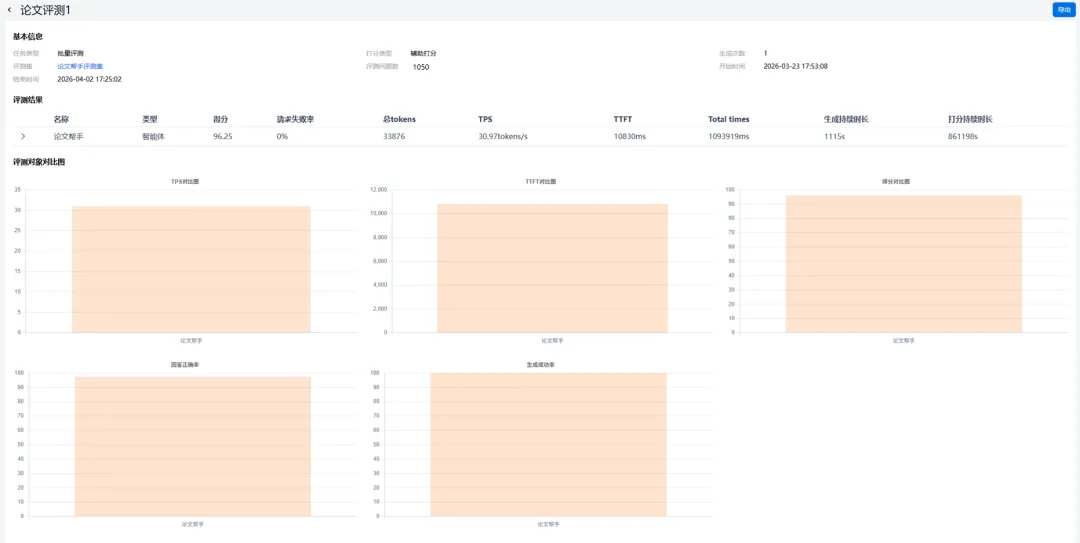
评测报告显示,“论文助手”的生成准确率达95%以上,响应稳定且请求失败率为零,达到了正式上线的标准。
第四步:数据闭环流转
应用上线后,通过元脑企智EPAI平台智能体应用日志模块,用户可记录线上的真实提问,同时可将这些日志数据导出并再次回流到数据集,从而自动扩充评测库,完成线上业务数据的闭环,确保“论文助手”随学术热点持续更新迭代。
04 结语
在大模型应用进入工业化生产的今天,评估已成为确保AI应用稳健落地的关键。元脑企智EPAI凭借数据闭环与自动化评测能力,解决了企业智能体应用评估难题。未来,元脑企智EPAI将持续深耕行业评测模板、多模态评估及安全性增强等前沿领域,助力企业在AI转型的浪潮中,走得更稳、更远。

 第七代服务器
第七代服务器