2026年初,以OpenClaw为代表的开源Agent项目在全球开发者社区迅速走红,折射出大模型应用范式正在经历的结构性转变——从“对话助手”迈向“自主Agent”。在Agent场景中,模型面对的是连续任务链中的工具调用、状态累积与循环决策,每一步的输出直接成为下一步的上下文输入。这意味着,模型任一环节的冗余不再只是局部损耗,而会沿整条链路持续叠加。
与此同时,MoE大模型虽已进入万亿参数阶段,但预训练过程中的专家效率问题却长期被忽视——大量算力消耗于低贡献结构,训练阶段的冗余在部署阶段被持续放大。当这样的模型被应用于Agent场景,其效率短板会在多步骤链路中会被成倍放大,演化为系统性瓶颈。
Yuan3.0 Ultra正是在此背景下提出的技术方案。作为当前业界仅有的三个万亿级开源多模态基础大模型之一,Yuan3.0 Ultra采用统一多模态架构,语言主干基于103层Transformer MoE构建,并引入LFA机制强化语义关系建模。训练初始参数1515B,经LAEP优化至1010B,推理激活参数68.8B,模型权重与技术报告已全面开源。
GitHub项目
https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra
论文链接
https://arxiv.org/abs/2601.14327
MoE架构的核心困境:专家负载分化问题
如果把MoE架构的大模型比作一个百人研发团队,它的核心优势本该是“专业分工、高效协作”:路由网络把每个token分配给对应的“专家模块”,只激活少量专家完成计算,既保证了模型的总容量上限,又能控制单次推理的计算开销。
但在真实的工程实践中,这个理想模型却出现了严重的“团队管理失控”。YuanLab.ai团队在研究中发现,MoE模型预训练过程中的专家负载演化,呈现出两阶段规律:
第一阶段为“初始过渡阶段”:训练早期受随机初始化影响,专家负载波动剧烈,同一专家收到的token数量在数量级上存在差异。
第二阶段为“稳定阶段”:负载趋于稳定,但稳定并不意味着均衡——实验数据显示,在不施加任何均衡约束的条件下,第32层负载最高与最低专家间的token比值达497.4×。更关键的是,一旦进入稳定阶段,各专家的负载排名就基本固定,分化具有结构固化性。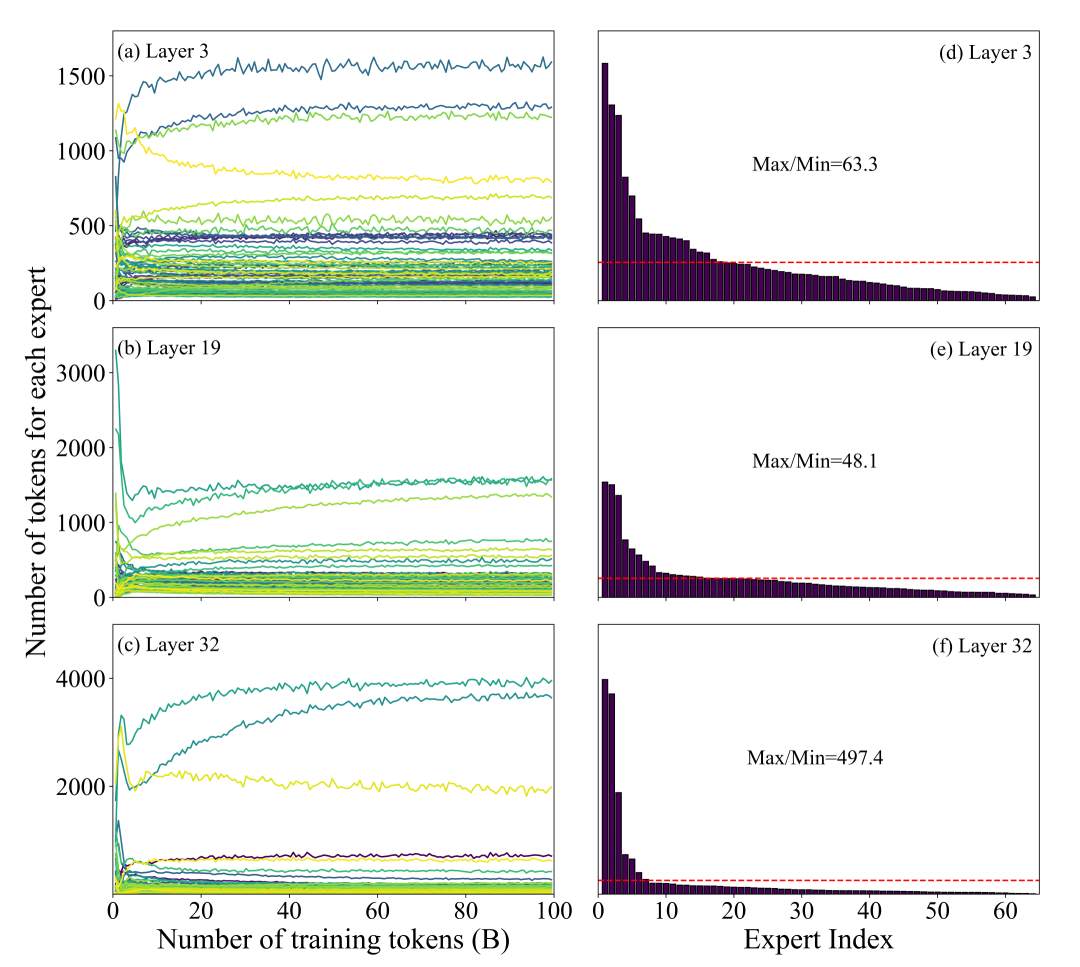
图 1:预训练过程中各层专家 token 分布的演化趋势(左列)及稳定阶段负载分布(右列)
简单来说,就是少数几个专家干了绝大多数的活,部分专家全程“摸鱼”,几乎没有参与有效学习。
更棘手的是,行业长期以来的解决方案,始终陷入“精度与均衡不可兼得”的死局。Mixtral、DeepSeek-V3等主流MoE模型普遍依赖辅助损失函数来约束专家利用率,却始终无法突破底层困境:准确性与负载均衡之间存在结构性权衡。系数调大(如 0.01)则负载得到均衡但模型精度下降;系数调小(如 0.0001)则精度有保障但同层内最大 token 差距仍可达 13.6 倍。DeepSeek-V3 选择 0.0001 这一极小系数,本质上是在二者之间的折中。以强制均衡损失对抗训练中自然形成的分工趋势,这一方向本身就值得重新审视。
LAEP:基于学习分工结构的自适应裁剪方法
MoE专家的负载分化并非简单的系统调度偏差,更大可能性是因为模型在大规模训练过程中自然形成的功能专一化结构(Functional Specialization)。在长期训练中,不同专家会逐渐对特定输入模式形成稳定偏好,从而在模型内部涌现出类似“专业模块”的分工格局。
这一现象与人类大脑的功能专一化机制具有明显的结构相似性:视觉皮层主要处理图像与空间信息,布罗卡区参与语言组织与表达,海马体负责新记忆的编码与巩固。这些功能区域的分化并非外部显式设计,而是在神经系统发育与长期经验积累过程中逐渐形成的稳定结构。
基于这一认识,优化目标不应简单地消除专家分化,而应区分具有功能意义的有效分化与长期低贡献的冗余结构。LAEP正是基于这一判断,利用预训练过程中自然积累的专家负载统计识别并移除冗余专家,在不引入额外损失函数、也不依赖任何下游任务数据的情况下实现结构优化。
LAEP(Layer-Adaptive Expert Pruning)通过裁剪判据和专家重排两步精准裁剪冗余专家并提高计算效率:
第一步,是无偏的冗余专家识别。LAEP以模型的每一层为单位独立判断,通过两个筛选条件的交集确定待移除专家:个体负载过低(低于层内平均的一定比例),且这批专家的累积贡献可忽略(不超过层内总token的一定比例)。两个条件的互补机制,既防止误删具有功能的专家,也约束单轮裁剪总量。
第二步,利用专家重排实现负载平滑。裁剪完成后,LAEP进一步引入专家重排算法:依据token负载统计对专家排序,以贪心策略将高负载与低负载专家交替分配到各计算设备,逐步平滑设备间负载分布,解决大规模分布式训练中的设备级不均衡问题。
最终,实现了亮眼的优化效果:
LAEP将Yuan3.0 Ultra将参数从1515B压缩至1010B(减少33.3%),训练TFLOPS从62.14提升至92.60,总效率提升49%——专家裁剪贡献32.4%,专家重排额外贡献15.9%。对比辅助损失方法(TFLOPS约为80,且需将损失系数调至远高于正常实践的0.01),LAEP在不调整任何训练超参数的情况下超越了这一水平。
表1:Yuan3.0 Ultra采用LAEP +专家重排机制有效提升机制训练效率
尤为关键的是:裁剪后的模型测试损失(1.658)反而低于未裁剪基准(1.661)。移除低贡献专家,不仅不损害模型性能,适度裁剪反而提升了整体学习效率——这与辅助损失方法“均衡代价是精度下降”形成直接对比。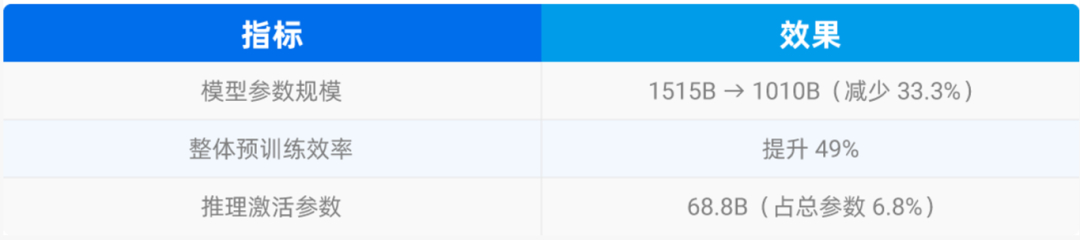
表2:Yuan3.0 Ultra模型参数与训练效率
改进RIRM,大幅减少Agent链路的“无效思考”
解决了训练阶段的结构冗余,Yuan3.0 Ultra把目光投向了推理阶段的另一大核心浪费——大模型的“过度反思”,而这一问题在 Agent 场景中,被放大到了极致。
在单轮对话中,模型在得出正确答案后反复验证、持续推演,只是多消耗一些token成本;但在Agent的连续任务链中,上一步的冗余输出,会直接成为下一步的上下文输入,单步的无效反思,会以任务步骤数为系数持续叠加,不仅会成倍增加算力成本,还会拉长系统响应延迟,甚至在反复推演中引入额外错误,导致整条任务链执行失败。
在Yuan3.0 Ultra Base的快思考强化学习(Fast-thinking RL)训练中,团队观察发现:模型在给出正确答案后并不主动终止推理,反思步骤超过3次的正确样本占相当比例,超过10次的情况同样不鲜见。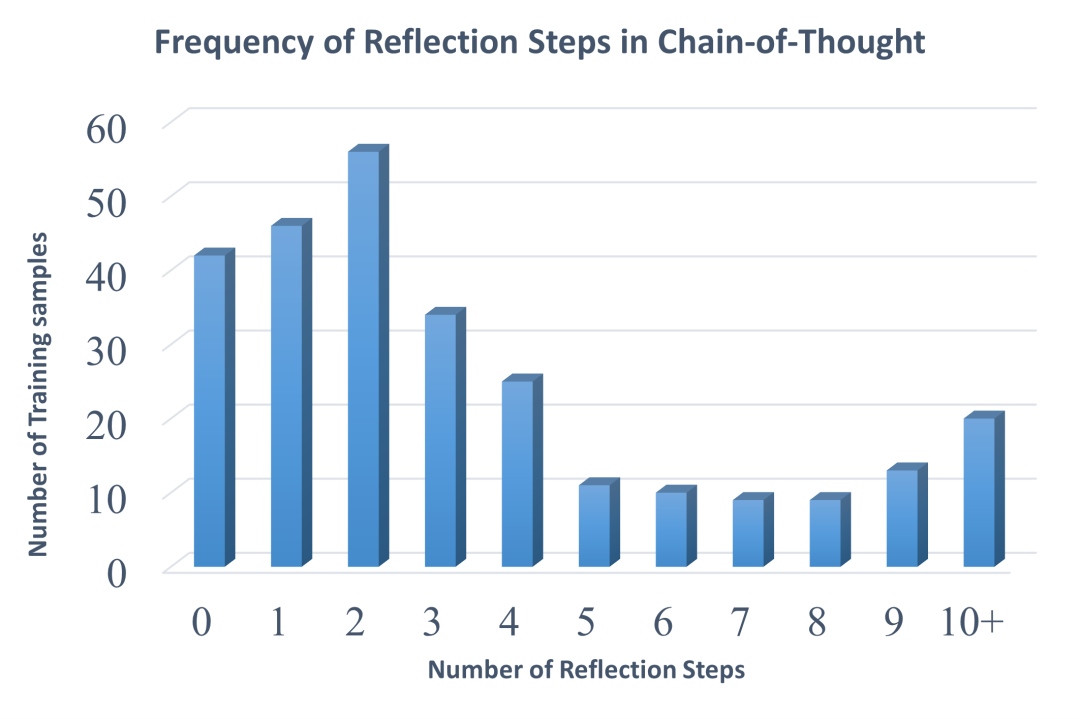
图 2:Yuan3.0 Ultra 快思考 RL 训练中正确样本的反思步骤频率分布
针对这一问题,Yuan3.0 Ultra 采用 RAPO(Reflection-aware Adaptive Policy Optimization)框架,并对其核心组件——反思抑制奖励机制(RIRM)进行了改进:引入随反思步骤数动态变化的奖励模式。答案正确时反思越少奖励越高,超过上限(默认 3 次)奖励归零;答案错误时反思步骤越多惩罚越重。这一连续奖励梯度取代了原先糟糙的步骤约束方式,对overthinking的抑制更加精准。
量化结果表明,改进后的RIRM使训练精度提升16.33%,同时将输出token长度降低14.38%——精度上升、冗余下降,二者同向优化。在Agent的多步骤任务链中,单步推理冗余会以步骤数为系数持续累积,RIRM将效率提升从单步收益转化为链路级的叠加收益。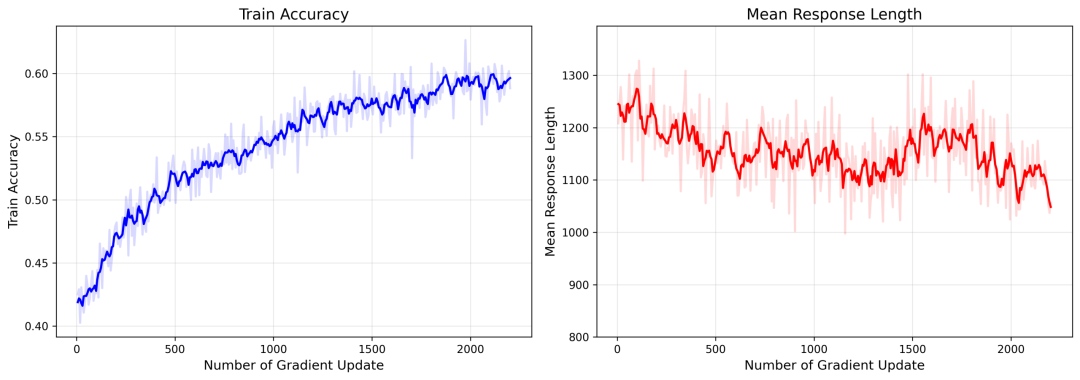
图3:训练动态。左:训练精度稳步提升;右:平均响应长度持续下降
从训练到推理,打通大模型效率优化闭环
Yuan3.0 Ultra的所有技术创新,最终都指向同一个目标:让大模型的强大能力,真正转化为企业可落地、可负担、可稳定使用的业务价值。
LAEP 针对训练阶段的结构冗余,RIRM 针对推理阶段的思考冗余:前者决定模型能力如何形成,后者决定模型能力如何被高效调用。二者共同构成 Yuan3.0 Ultra 面向 Agent 场景的完整效率优化框架。
Yuan3.0 Ultra的技术内核指向的是一条更具方法论意义的发展路径:训练阶段,顺应MoE专家分化的学习规律,裁除冗余保留有效分工;推理阶段,使模型在不同复杂度任务下精准控制推理深度。从 Yuan3.0 Flash到Yuan3.0 Ultra,技术演进脉络清晰:Flash版本聚焦推理端效率,Ultra版本聚焦训练端效率,二者共同指向同一目标:提升单位算力所产生的真实智能密度。
代码开源链接
https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra
论文链接
https://arxiv.org/abs/2601.14327
模型下载链接
1)Huggingface:
https://huggingface.co/YuanLabAI/Yuan3.0-Ultra-int4
2)ModelScope:
https://modelscope.cn/models/YuanLabAI/Yuan3.0-Ultra-int4
3)始智AI:
https://www.wisemodel.cn/models/YuanLabAI/Yuan3.0-Ultra-int4

 第七代服务器
第七代服务器














 访问 AIStore
访问 AIStore