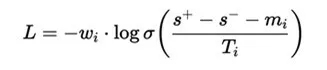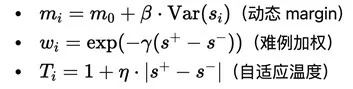近日,浪潮信息AI团队正式发布"源"Yuan-EB 2.0系列模型(Yuan-embedding-2.0,嵌入模型)。根据HuggingFace权威评测榜单MTEB和C-MTEB最新更新显示,"源"Yuan-EB 2.0模型在检索任务(Retrieval)与排序任务(Reranking)双榜单中,斩获"双SOTA"的绝佳成绩。中文模型在C-MTEB榜单检索任务获得81.76分、排序任务获得77.94分;英文模型在MTEB榜单检索任务获得70.69分、排序任务获得53.27分,展现了其在自然语言处理领域的强大能力。尤其值得关注的是,"源"Yuan-EB 2.0模型仅以0.3B和0.6B的轻量级参数规模,全面超越众多大参数量主流模型,树立了"小参数、高性能、低开销"的技术新标杆,为检索增强生成(RAG)、语义搜索等应用落地提供了更优的技术方案。
权威评测霸榜:源Yuan-EB 2.0斩获检索与排序任务双项第一
"源"Yuan-EB 2.0系列模型由浪潮信息自主研发,创新性地利用源大模型进行高质量训练数据构建,通过强化型Reranker损失函数、多阶段渐进式训练方案、动态难负例挖掘等技术突破,显著提升了模型在检索与排序任务上的表现。作为RAG系统的核心组件,嵌入模型负责将文本转换为向量形式,直接决定检索的精准性和效率。"源"Yuan-EB 2.0模型包括中文和英文两个模型,分别针对中英文语义特性进行深度优化,并在医疗、法律、金融、电商等垂直领域进行针对性训练,确保模型在专业场景下的优异表现。
MTEB和C-MTEB是国际公认的嵌入模型评测基准,涵盖检索、排序、分类等多项任务。"源"Yuan-EB 2.0模型在检索与排序两大核心任务上夺得SOTA成绩,意味着其能够更精准地理解用户意图、更高效地匹配相关内容,为智能问答、知识库检索、文档分析等RAG应用提供更可靠的技术支撑。
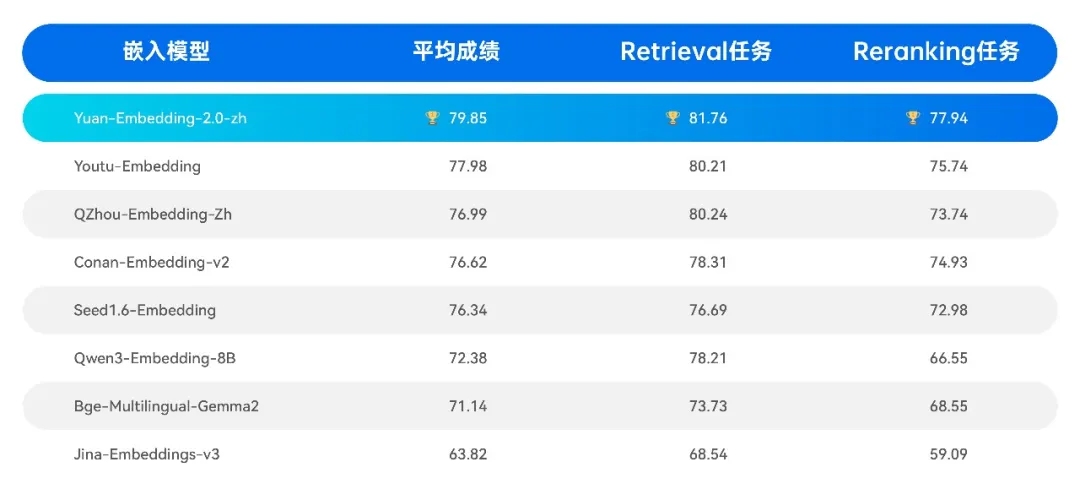
■ 中文版本,C-MTEB榜单
C-MTEB(Chinese Massive Text Embedding Benchmark)是业界公认的中文Embedding模型权威评测基准,涵盖Classification、Clustering、Pair Classification、Reranking、Retrieval、STS等六大任务类型,共35个公开数据集。Yuan-embedding-2.0-zh在Retrieval和Reranking任务上表现突出,分别以81.76分和77.94分的成绩夺得双料冠军,全面超越业界主流大参数量模型,展现了卓越的中文语义理解与检索能力。
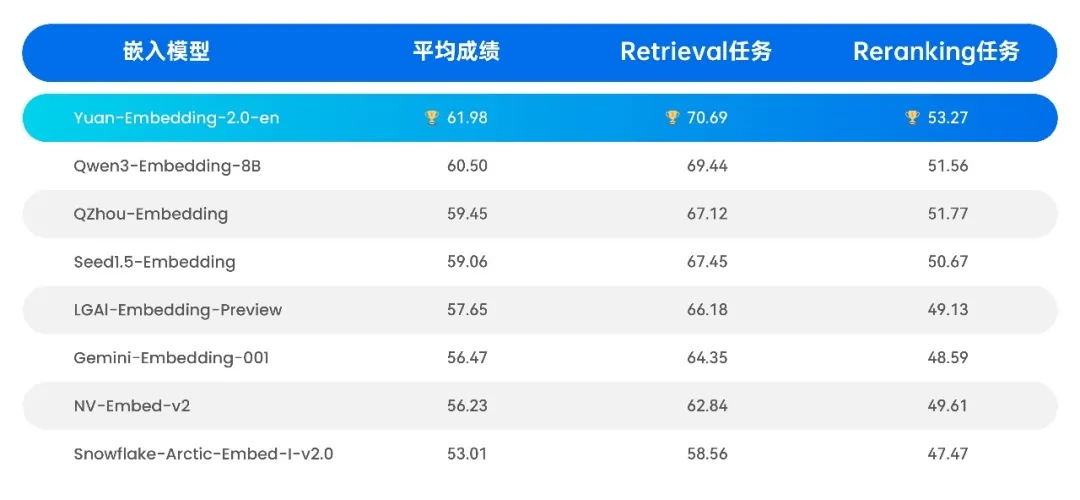
■ 英文版本:MTEB榜单
MTEB(Massive Text Embedding Benchmark)是全球最权威的多语言Embedding模型评测基准,涵盖8大任务类型、58个数据集、112种语言。其中英文评测集作为最具竞争力的赛道,汇聚了全球顶尖Embedding模型。Yuan-embedding-2.0-en英文版本在该榜单中取得突破性成绩,在Retrieval任务获得70.69分、Reranking任务获得53.27分,仅以0.6B的轻量级参数规模击败众多大参数模型,充分证明了其技术创新的有效性和先进性。
源Yuan-EB 2.0树立“小参数、高性能、低开销”技术新标杆
“源”Yuan-EB 2.0模型以轻量级的 0.3B 和 0.6B 参数规模,实现了对诸多大参数模型的性能反超,重新定义了“小参数、高性能、低开销”的技术新标杆,其背后得益于研发团队在技术架构与训练方法上的多项原创性创新:
强化型Reranker损失函数
浪潮信息AI团队设计了一种创新的强化型Reranker损失函数,通过三个自适应机制的协同作用,实现了训练过程的智能化调节:
其中:
■ 动态Margin机制:基于样本得分方差自动调整优化目标,当模型对样本区分度高时提升margin要求,反之则适当降低,实现因材施教的训练效果;
■ 难例加权策略:采用指数衰减函数自动识别并重点优化边界样本,将计算资源聚焦在真正有价值的难分样本上,大幅提升训练效率;
■ 自适应温度调节:根据正负样本得分差距动态调整损失函数的陡峭程度,有效防止对简单样本的过拟合,增强模型泛化能力;
这种三位一体的设计使得损失函数能够智能感知样本特性并自动调整优化策略,显著提升了Reranking任务的精排能力。该方法具有自动聚焦难样本、避免过度拟合易样本的优势,训练过程稳定、收敛快,同时对搜索、问答、对话等不同任务场景展现出强大的适应性。
多阶段渐进式训练
模型训练采用精心设计的多阶段渐进式方案:
■ 大规模弱监督预训练:利用海量配对数据进行对比学习,构建扎实的语义表征基础;
■ 高质量监督微调:基于人工标注的高质量数据集进行精细化训练,提升模型在特定任务上的表现;
■ 任务特定优化:针对Retrieval和Reranking任务分别设计优化策略,充分发挥模型在不同场景下的潜力;
动态难负例挖掘
浪潮信息AI团队创新性地提出了动态难负例挖掘方法,在训练过程中实时识别并利用高质量负样本,能够提供:
■ 自动过滤伪负例,避免噪声样本对模型训练的干扰;
■ 动态调整负例难度,确保模型始终在最佳学习区间内训练;
■ 有效提升模型对细粒度语义差异的判别能力;
多语言深度优化
针对语言特性进行专项优化:
■ 语义理解增强:针对中英文语言的词语搭配、语法结构和语义关联特点进行深度训练,准确捕捉不同语言表达的细微语义差异;
■ 多领域覆盖:在通用领域和垂直行业场景中进行广泛训练,提升模型对不同领域文本的检索和排序能力;
■ 高效编码与泛化:优化文本的向量表征效率,通过多样化数据训练增强模型在不同应用场景下的泛化能力,在保持高精度的同时提升检索响应速度;
元脑企智EPAI平台集成“源”Yuan-EB 2.0模型,加速知识库构建与性能提升
目前,"源"Yuan-EB 2.0模型现已完成在元脑企智EPAI平台的全面部署。针对智能搜索、RAG增强、智能客服等业务需求,企业用户可直接在平台上调用该模型,体验低算力成本下的极致语义理解与精排效果。通过与元脑企智EPAI平台多阶段RAG检索增强技术,实现企业私有数据、行业专业知识与通用知识的高效整合,攻克大模型知识时效性难题,为业务场景提供精准、专业的生成内容保障。
依托元脑企智EPAI平台完整的工具链支持,企业无需深厚的技术技术积累即可快速搭建智能应用。"源"Yuan-EB 2.0模型优异的检索与排序性能,配合平台的一站式开发能力,使企业能够以更低成本、更高效率构建专属知识库系统,切实释放数据价值,全面提升企业的智能化水平。
开源地址如下,开发者可通过以下方式下载体验
👉 中文版本
◇ HuggingFace链接:https://huggingface.co/IEITYuan/Yuan-embedding-2.0-zh
◇ ModelScope链接:https://modelscope.cn/models/IEITYuan/Yuan-embedding-2.0-zh
◇ 始智AI链接:https://www.wisemodel.cn/models/IEIT-Yuan/Yuan-embedding-2.0-zh
👉 英文版本
◇ HuggingFace链接:https://huggingface.co/IEITYuan/Yuan-embedding-2.0-en
◇ ModelScope链接:https://modelscope.cn/models/IEITYuan/Yuan-embedding-2.0-en
◇ 始智AI链接:https://www.wisemodel.cn/models/IEIT-Yuan/Yuan-embedding-2.0-en

 第七代服务器
第七代服务器