大模型推理正在向长上下文、高并发方向快速演进,KVCache通过缓存历史token的K/V向量,将注意力计算的二次方复杂度降为线性,是提升解码效率的核心机制。然而,随着上下文长度增长、请求量指数级上升,KVCache存储规模急剧膨胀,单机显存容量成为首要瓶颈。业界被迫采用分布式部署,却陷入新的困境:跨节点共享面临统一池化与本地缓存的方案两难,高内存利用率与低数据访问延迟难以兼顾。存储与共享双层困境叠加,基于RDMA网络的传统方案已难以承载。
为破解上述难题,元脑KOS基于CXL(Compute Express Link)内存池化技术推出KVCache管理系统MantaKV。实测数据显示,MantaKV使跨节点RPC通信延迟降低约80%,相比400Gbps RDMA网络方案,MantaKV降低主机接口卡成本87%、交换机成本63%,每64GB/s带宽建设成本下降27%,为长上下文、高并发大模型推理提供可拓展、高吞吐、低延迟的内存基础设施。

01 KVCache:大模型推理的效率引擎与双重困境
KVCache通过缓存历史token的K/V向量,将注意力计算的二次方复杂度降为线性,显著加速推理过程,被认为是大模型推理的“效率引擎”。然而,随着上下文长度不断增长、请求量指数级上升,KVCache面临严峻的存储与共享双重困境:
存储困境:基于RDMA网络的分布式内存拓展方案存在三方面弊端
长上下文场景下,KVCache规模爆炸式增长,GPU HBM容量难以承载,必须将部分KVCache分层卸载至主机内存,单机显存容量不足成为首要瓶颈。为了突破单机限制,业界普遍采用基于RDMA网络的分布式内存扩展方案——通过InfiniBand等高速网络将多台服务器的内存池化共享,却存在以下弊端:
■ 带宽争抢:多节点同时访问热点数据时共享RDMA网络通道,易在热点节点形成带宽争抢。
■ 通信干扰:KVCache读写流量与模型并行通信流量在RDMA网络上混合传输,相互干扰导致推理吞吐忽高忽低。
■ 成本高昂:专用RDMA网卡与高速交换机构建成本极高,每64GB/s带宽建设成本约为数万美元级别。
02 共享困境:多节点共享KVCache现有方案无法兼顾内存利用率与数据访问延迟
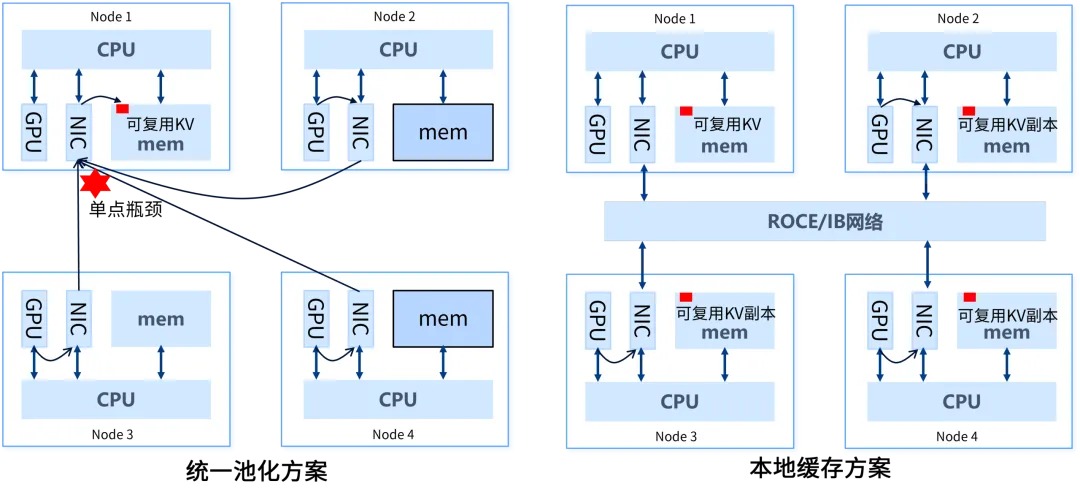
分布式环境下,为了实现跨节点共享KVCache,业界通常在两种技术方案中抉择:统一池化方案与本地缓存方案。然而,由于这两种方案都构建于RDMA/RPC等网络传输技术之上,数据必须经过“协议解析-数据拷贝-网络传输”的完整流程,无法规避协议开销,导致了高内存利用率与低数据访问延迟不可兼得。
■ 统一池化方案:将集群中各节点的内存聚合成一个全局资源池,所有KVCache集中存储于逻辑池中。其优势在于内存利用率高——KVCache仅需存储一份,整个集群的内存空间被充分利用;其弊端则在于,当计算节点需要读取KVCache时,必须通过网络向存储节点发起请求,数据需要经历协议解析、数据拷贝、网络传输等层层环节,这导致传输延迟增高,并且在高并发场景下热点存储节点极易成为带宽瓶颈。
■ 本地缓存方案:在各节点本地冗余存储热点KVCache(即被频繁访问的KVCache),当节点需要数据时可直接从本地内存读取,因而延迟极低。但其代价是——同一热点KVCache需要在多个节点各存一份,产生大量重复副本,浪费内存空间。同时,为了保持这些副本的一致性,节点间仍需通过网络进行数据同步,无法避免网络传输的协议开销。
03 元脑KOS推出KVCache管理系统MantaKV
针对KVCache的存储与共享瓶颈,元脑KOS推出基于CXL池化内存技术的KVCache管理系统MantaKV,以池化内存突破单机显存限制,并以统一地址空间实现跨节点高效共享。
基于MantaKV的KVCache管理机制
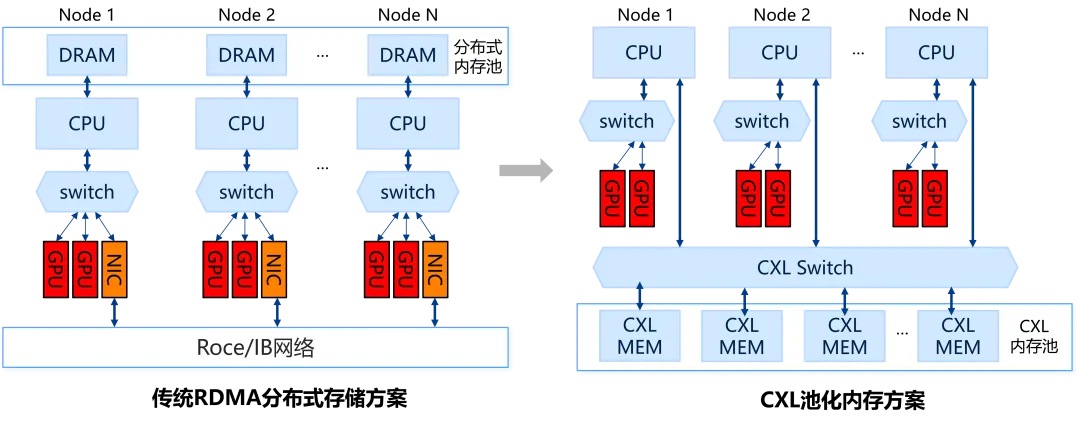
■ CXL池化内存破解传统RDMA分布式存储架构限制
面对KVCache规模急剧膨胀、存储需求激增的现状,MantaKV采用CXL池化内存技术突破传统RDMA架构的限制:
针对带宽争抢的问题,MantaKV采用独立于RDMA网络的CXL专用物理通道,使多节点可直接并行访问热点数据,不存在网卡单点瓶颈,从而消除多节点并发访问时的带宽竞争,实现稳定低延迟访问。
针对通信干扰的问题,MantaKV通过CXL控制器建立KVCache专用数据通道——KVCache读写流量通过CXL链路传输,而模型并行(如张量并行、流水线并行)的通信流量仍通过RDMA网络传输,两类流量在物理硬件层面完全分离、各行其道,避免流量混合导致相互干扰,保障推理吞吐稳定性。
针对KVCache“存得贵”的问题,MantaKV利用CXL内存扩展方案替代专用RDMA网卡与高速InfiniBand交换机,在突破单机显存容量限制的同时,降低主机接口卡成本87%、交换机成本63%,每64GB/s带宽建设成本下降27%,实现更优整体性价比。
■ 内存级共享打破高内存利用率与低访问延迟两难
针对分布式环境下多节点共享KVCache时内存利用率、数据访问延迟难以兼得的困境,MantaKV基于CXL池化内存技术构建了跨节点共享内存通信架构,将节点间交互从“网络传输范式”升级为“内存级直接访问”,打破“高利用率必高延迟”的两难。
针对统一池化方案的消息通信延迟高问题,MantaKV以内存读写语义替代复杂的RPC协议处理,从根本上规避协议解析、数据拷贝与网络传输等层层开销,使跨节点访问延迟从传统网络的数十微秒降至接近本地内存的纳秒级(实测RPC延迟降低约80%),用户可以获得本地缓存般的低延迟体验。
针对本地缓存方案的副本冗余、内存浪费问题,MantaKV基于CXL统一地址空间构建集中式存储架构,使跨节点访问延迟降至内存级别,彻底摆脱对本地冗余缓存的依赖——所有KVCache集中存储于统一资源池即可被各节点直接远程访问,既消除了重复副本对内存空间的占用,又避免了多副本间同步带来的带宽浪费与一致性维护开销。
MantaKV基于CXL池化内存技术,以内存级速度突破单机显存瓶颈并规避RDMA扩展的性能与成本代价,以内存级共享打破内存利用率与数据访问延迟不可兼得的两难,在降低网络基础设施成本的同时,为长上下文、高并发大模型推理提供可拓展、高吞吐、低延迟的内存基础设施。

 第七代服务器
第七代服务器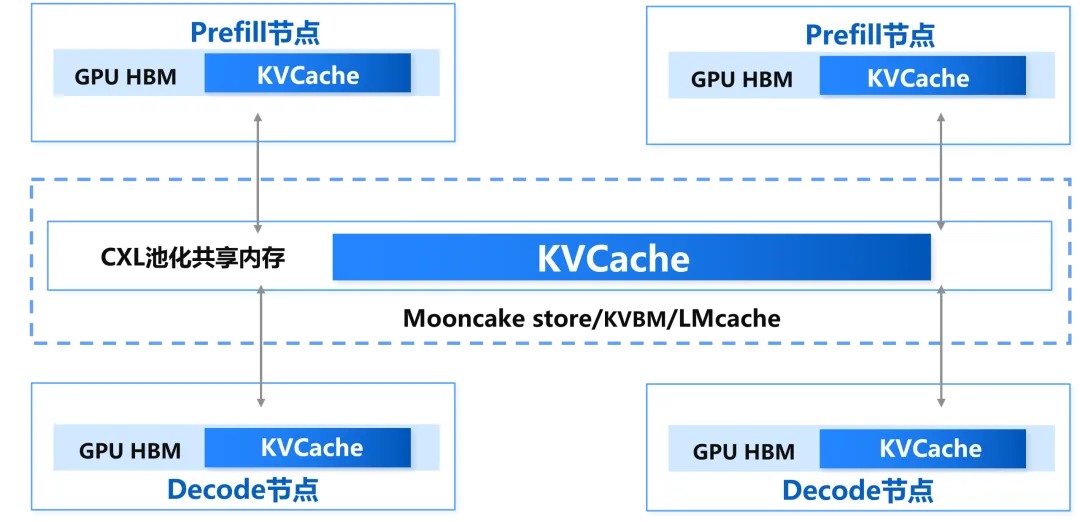














 访问 AIStore
访问 AIStore