前不久,浪潮信息研究团队提出了一个用于智能驾驶的持续强化学习框架Gr-LafRL(Latent fine-tuning continual RL with implicit Generative replay,具有隐式生成重放的潜在微调可持续强化学习),有效的解决了智能驾驶持续强化学习中普遍存在的灾难性遗忘、训练效率低下等问题,大幅提高了智能驾驶模型持续强化学习的训练效率。测试结果显示,新框架生成100万个样本仅需要60秒,速度提升了16.7倍,打破了智驾模型强化学习过程中的训练样本生成瓶颈,而且平均每次策略更新时间仅为传统方法的1/3。
解决智驾强化学习的挑战:效率低、学新忘旧
强化学习在解决序列决策问题和控制任务方面显示出越来越强大的能力,使得强化学习技术路线有望超过rule-based的传统智驾技术路线,成为智驾的主流技术路线。但是,即便如此,智能驾驶模型的强化学习仍然面临学习效率低、遗忘等一系列挑战。
规模限制带来了灾难性遗忘挑战。智驾模型的延时敏感和车载算力的约束极大限制了智驾模型的规模。以响应延迟为例,智驾过程被切分为一个个连续的马尔科夫决策过程,每个过程的智驾系统决策时间不超过100ms,留给智驾模型的反应时间被严格限制在10ms量级,远低于LLM。有限的规模使得智驾模型的遗忘问题尤为突出,在持续学习中,经常会因为近期经验覆盖以往经验,出现灾难性遗忘,造成模型训练的震荡不收敛。
传统的强化学习没有区分策略和控制,导致训练效率不高。算法主要学习控制动作,需要系统在整个状态和动作空间中进行探索,但是智驾应用中状态空间、动作空间非常大,比如不同场景下的方向盘、油门等组合无穷尽,导致模型“学不过来”;二是模型需要学习海量的动作才能涌现出不同层级的策略能力,因而模型的策略能力普遍有限,所以经常违背车辆运动约束,输出车辆不可能执行的控制指令,比如高速行驶中的突然转弯等;三是动作空间中的控制动作太细碎,比如“方向盘左转10度”,不同场景几乎无法复用,导致模型泛化能力很弱。
数据结构一直是训练效率的瓶颈。智驾模型输入数据是图像、激光雷达点云、毫米波雷达信号、车辆运动参数等多维、强耦合的“多模态异构数据”,训练消耗算力高、数据复用率低。长尾场景一直是智驾模型训练的主要挑战,这类场景出现概率低,数据收集难度大,主要依靠仿真生成,但是由于生成模型不掌握场景数据分布规律,生成的场景样本数据质量不高,与真实场景存在分布差异,而且由于数据结构的高度复杂,生成这些数据的算力和时间消耗非常大,经常成为训练的瓶颈。
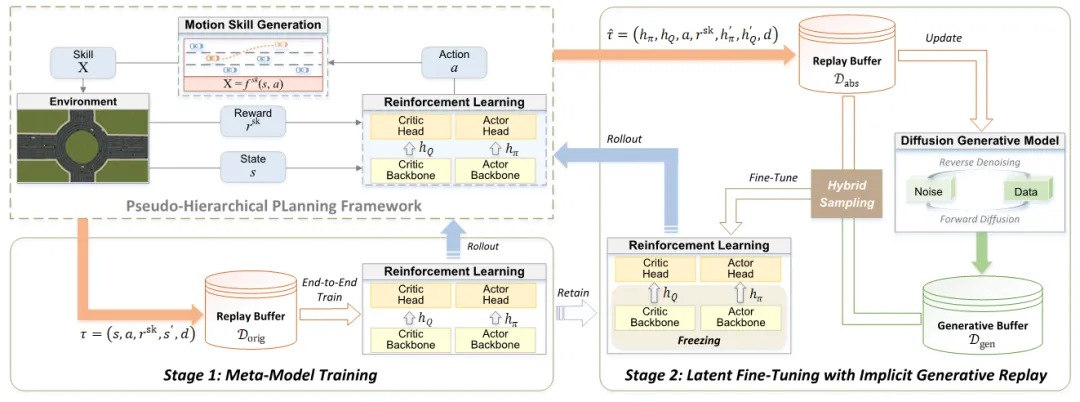
针对这些问题,浪潮信息利用最新的元学习技术,开发了两阶段框架,以冻结骨干网来解决模型遗忘问题,然后引入伪分层规划结构,将算法分为策略和控制两层,从整体上简化模型训练。最后通过潜在微调将场景样本生成和训练从高维度数据转变为潜在数据、伪经验,辅以混合数据采样,大大降低了计算复杂度,提高模型训练的收敛速度。
两阶段学习解决遗忘难题
Gr-LafRL的两阶段框架如下:
第一阶段端到端预训练“元模型”,让骨干网络掌握识别交通密度、道路拓扑等通用的环境特征编码能力,然后冻结骨干网,保证基本的通用技能不被覆盖,同时减少后续适配新场景的特征学习成本;
第二阶段用潜在数据微调和强化头部网络,聚焦策略优化,使样本利用效率提升,有效提高训练效率,实验数据显示,该框架仅需传统强化学习2/3的迭代步数即可超越ASAP-RL等基线模型。
 Gr-lafRL逻辑框架
Gr-lafRL逻辑框架
伪分层规划结构让学习大幅简化
Gr-LafRL用伪分层规划结构将强化学习进行结构升级,将其拆分为策略和控制两层,策略层负责决策,控制层负责将策略变成具体的控制动作,两层之间并非独立,是依靠参数绑定在一起的,兼顾了灵活性和效率。这样模型仅需要对策略层进行训练优化即可,相当于让模型只学习技能,而不必学习动作,大大简化了模型学习的复杂度,训练效率大幅提高。而且,参数化绑定的策略与控制结构,避免了传统强化学习输出“不可能的动作”的弊端,又可以适配复杂交通场景需求,在基于MetaDrive模拟器的多场景测试中,该结构使路线完成率RC稳定在90%以上。
隐式生成重放,解决智驾场景样本生成瓶颈
在训练数据生成方面,Gr-LafRL创新的采用了隐式生成重放技术,将既往经验压缩为潜在数据,并基于潜在数据生成“伪经验”来微调模型。潜在数据就是对既往的训练经验进行抽象、压缩处理,形成“数据的精华版”,数据维度低、信息密度高,比如对图像进行卷积压缩成几百维的特征向量,向量里包含了 “道路边缘、车辆位置” 等关键信息,丢掉了冗余的像素细节。
Gr-LafRL集成了专门的轻量化扩散模型,基于潜在数据生成“伪经验”。“伪经验”保留了场景的数据分布规律,比潜在数据信息密度更高,也保留了维度低、结构简单的特点,大幅降低了样本生成的计算复杂度,生成速度快,解决了 “生成质量” 与 “计算效率” 的矛盾,生成100万个样本仅需要60秒,而传统算法生成100万样本至少需要1000秒。由于“伪经验”信息密度高、结构简单,用“伪经验”微调模型不仅极大提高了每次迭代的效果,也大幅缩短了每次迭代的时间,在实际测试中,每100次策略更新仅需要9秒,约为常规训练时间的三分之一。
混合数据采样,更好平衡经验增强与探索能力
生成式重放主要是增强模型的历史经验,随着强化学习的迭代,“伪经验”会越来越落后于当前的环境,为此,工程师精心设计了一个衰减的伪经验使用系数,这个系数会随着迭代逐步降低,直至为0。这样,通过“伪经验”与在线经验的混合采样使用,有效利用了经验数据,也避免了经验对后续迭代的限制,保证了模型增强探索、突破旧有藩篱的能力。
测试——2/3迭代即可超越业界主流基准模型
工程师采用了MetaDrive模拟器创建交通环境,对Gr-LafRL框架与各个主流的算法进行了对比。环岛是动态性最强的驾驶场景之一,工程师用模拟器创建了单环岛、双环岛、十字路口等3个动态环境,每个环境都通过一系列随机参数生成路障和交通车辆,智驾车辆的目标是在动态交通中安全行驶,避免碰撞和违法。
PPO、SAC等下表中所列出的对比算法,都是强化学习领域常用的基准模型,各有长处,其中ASAP-RL(Aligning Simulation and Real -Reinforcement Learning,模拟与真实世界对齐强化算法),有着突出的泛化能力,本文只展开论述Gr-LafRL、LafRL(未采用潜在微调的Gr-LafRL)同ASAP-RL的对比结果。
Evaluation results of learned policies in Env 0.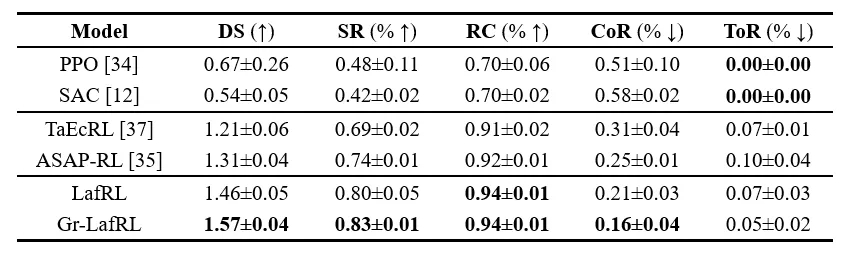 备注:DS为综合评分,SR为成功率,RC为路线完成率,CoR为碰撞率,ToR为超时率
备注:DS为综合评分,SR为成功率,RC为路线完成率,CoR为碰撞率,ToR为超时率
工程师先在单环岛环境(环境0)中进行了训练。结果显示,在前30000次迭代中,即使采用随机初始化,Gr-LafRL和LafRL都表现出与ASAP-RL相当的性能,在进入到潜在微调阶段后,Gr-LafRL的渐进性能明显优于LafRL,收敛更快,只需要三分之一的迭代次数就能超过ASAP-RL,隐式生成回放与混合采样算法作用非常明显。
LafRL和Gr-LafRL在其主干网络中培养出足够的能力后,通过潜在微调优化了最优策略,最终实现了更优异的驾驶性能。Gr-LafRL通过整合隐式生成重放进一步提升了大多数指标,相比ASAP-RL,成功率SR高出9%,碰撞率CoR低5%,超时率ToR低2%。
工程师将训练好的模型迁移到双环岛环境和十字路口两个环境中,对模型的泛化能力进行比较。结果显示,Gr-LafRL的元模型直接迁移到两个场景后,即使不进行适配,也能有效运行,体现了元模型领先的泛化能力。在模型的适配过程中,Gr-LafRL在稳定性和效率上优于LafRL,在少于20%的迭代次数内就达到了与ASAP-RL相当的收敛水平。
本研究得到了北京市科学技术协会青年科技人才托举工程的支持。
*成果论文题为《Continual Reinforcement Learning with Implicit Generative Replay for Autonomous Driving》,发表于European Conference on Computer Vision(欧洲视觉 计算大会,简称ECCV),该会议是计算机视觉领域三大顶会之一,其Workshop聚焦前沿技术落地场景,要求研究成果兼具理论创新性与工程实用性,尤其关注自动驾驶、机器人等复杂现实问题的解决方案,在行业内具有重要技术风向标意义。
注:本文转载自“元脑实验室”官微

 第七代服务器
第七代服务器













 访问 AIStore
访问 AIStore