浪潮信息研究团队开源面向VLA大模型的自动驾驶计算加速框架AutoDRRT 3.0。该框架基于浪潮信息自动驾驶车载计算平台EIS400,针对复杂语义推理及极端长尾场景,通过在计算效率、通信延时、任务调度三大维度的创新重构,将10亿级参数VLA模型的整体端到端延时降低至78ms,彻底打破了VLA模型在车端的工程化瓶颈。目前,AutoDRRT 系列框架结合自动驾驶车载计算平台EIS400,面向2D+CNN小模型、BEV+Transfomer大模型、VLA大模型不同算法进行了针对性的算法内核与架构升级,大幅降低自动驾驶端到端链路延时,汽车厂商、软件平台商和中间件软件开发商可免费下载使用。
 AutoDRRT 3.0开源
AutoDRRT 3.0开源
VLA大模型是一种将视觉感知、自然语言理解与动作控制统一到同一框架的人工智能模型,能够直接从感知输入生成驾驶控制指令,实现从“看”到“懂”再到“行”的完整闭环。但在VLA大模型迈向实车部署的关键阶段,模型规模的指数级增长与车载计算平台有限算力和能耗预算之间的矛盾日益凸显。随着参数量从千万级跃迁至数十亿甚至百亿级,模型对计算能力、存储带宽与系统协同效率提出了前所未有的挑战。
■ 延时挑战,算力需求骤增与串行推理逻辑的博弈:VLA 将视觉感知、语义理解与动作生成统一到同一模型中,推理过程呈现多阶段强依赖特征,计算链路显著拉长,时延天然呈串行累积。同时VLA大模型采用Transformer架构,自注意力计算复杂度随序列长度指数增长,且自回归生成导致动作指令必须串行产出,这种逻辑依赖限制了硬件并行度。另外,数十亿级参数量迫使芯片频繁访存,受限于端侧内存带宽,导致计算单元常因“等数据”而空转,成为时延瓶颈的重要来源。
■ 通信挑战,多模态数据流转与传统中间件开销的冲突:与传统模块化系统相比,VLA大模型对数据通信的压力呈指数级增长。一方面,模型输入输出数据规模巨大,多模态特征、高清图像及中间张量频繁在不同计算单元间流转;另一方面,端到端闭环对时延极为敏感,任何一次不必要的拷贝或序列化都会被直接放大为系统级响应抖动。传统基于中间件的通信机制在设计之初更侧重通用性与解耦性,其多次拷贝、序列化与协议栈开销在VLA大模型场景下逐渐成为制约实时性的核心瓶颈。
■ 调度挑战,异构算力碎片化与复杂任务负载的不匹配:自动驾驶VLA大模型的执行过程具有明显的异构性与阶段性特征,数据预处理、逻辑控制主要运行在CPU侧,而大规模视觉推理、多模态融合等工作则高度依赖AI算力。同时,不同子任务在实时性、计算量与优先级上差异显著,既包含毫秒级强实时任务,也包含吞吐导向的重计算任务。传统以线程或进程为粒度的粗放式调度方式,难以应对VLA大模型多任务并发、强优先级约束与异构算力协同的执行需求,容易导致关键任务被阻塞、算力资源空转或端到端时延不可预测。
全新开源AutoDRRT 3.0,加速自动驾驶VLA大模型落地
针对VLA大模型上车挑战,浪潮信息研究团队对AutoDRRT进行了一次彻底的系统重构,通过计算、通信、调度全面革新,系统解决VLA大模型实时推理问题。
■ 计算革新, “感知-推理-控制”全闭环加速引擎
针对VLA大模型在车端推理过程中普遍存在的计算链路冗长、内存访问频繁以及自回归生成机制引发的指令输出阻塞等问题,AutoDRRT 3.0从计算内核层面对VLA推理链路进行重构,通过并行化优化、视觉剪枝、算子融合等技术,实现了从“视觉输入”到“动作输出”的全闭环加速。
 AutoDRRT 3.0典型场景运行效果图
AutoDRRT 3.0典型场景运行效果图
并行解码:针对VLA模型自回归生成导致的串行延时问题,AutoDRRT 3.0适配了先进的并行解码技术。通过将单步预测演进为“时域序列预测”,系统能够在一个推理周期内并行产出未来多步的动作指令。这不仅消除了逐个Token产出的逻辑依赖,释放了异构硬件的并行计算潜能,更确保了模型在较低的推理频率下,依然能输出高频、平滑、连续的控制序列。
视觉剪枝:引入面向自动驾驶场景的视觉剪枝技术方案,该方案通过衡量特征向量间的余弦距离,在无须模型微调的前提下,实现了对冗余视觉信息的极高比例压缩。与传统依赖注意力权重的剪枝策略相比,该方案有效解决了注意力分布“平滑化”导致的关键感知目标(如远端小障碍物、边缘突发路况)被误剔除的风险。
算子融合与混合量化:实施异构精度策略,针对视觉Transformer实施 INT8 PTQ量化,在保持高分辨率感知精度的同时显著提升吞吐;对语言内核采用W4A16量化,突破访存带宽瓶颈。同时,针对Transformer网络进行深度算子融合与加速,并将部分网络高频操作前移至预处理阶段,彻底消除推理过程中的冗余计算。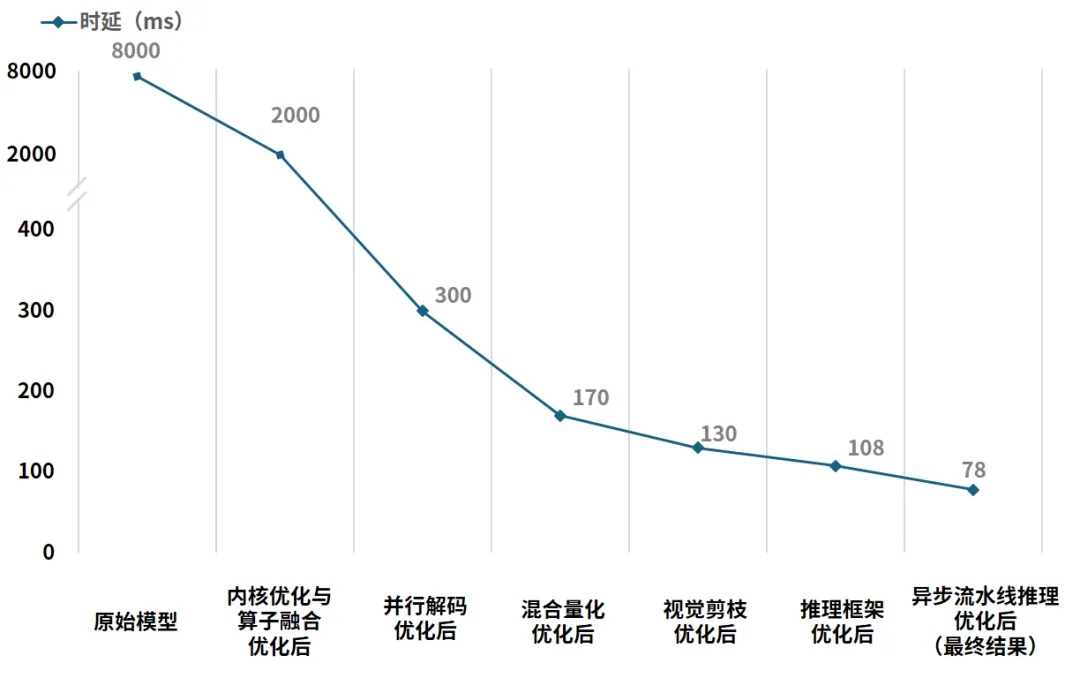
AutoDRRT3.0计算优化技术对VLA大模型推理延时降低效果对比
通过对计算内核与调度逻辑的深度重构,成功将10亿级参数VLA大模型的端到端推理时延从8000ms降低到78ms,其中并行解码模块将时延从2000ms降低至300ms,视觉剪枝模块将时延从170ms降低至130ms,整体性能提升102倍,实现了大模型在车载端侧的实时闭环。这是业内首个开源、且在智驾域控平台上将VLA大模型端到端推理时延稳定压缩至 100ms 以内的计算加速框架,为 VLA 大模型在车端规模化部署提供了可验证的工程级支撑。
■ 通信革新:异构单元高性能通信机制
为全面释放VLA大模型在智驾系统中的实时响应潜能,AutoDRRT 3.0针对传统中间件在大数据传输中的效率瓶颈,从底层重构了面向异构计算单元的统一高性能通信机制。该机制深度覆盖CPU-CPU、CPU-GPU及GPU-GPU等全场景数据通路,彻底打通了跨单元协作的“信息高速公路”。
AutoDRRT 3.0为通信机制构建“轻量调度+极速流转”的混合模式。轻量调度模式将通信通道解构为微秒级的“逻辑信令”通路,专注于节点间的精细调度与同步唤醒;极速模式为重负载的大数据提供共享内存,相当于走“独立高速路”,从根本上革除了传统DDS协议在大数据通信中的序列化损耗与冗余拷贝代价。该方案针对异构计算形态提供了三位一体的优化路径:在CPU内部实现跨进程零拷贝;在CPU与GPU之间通过地址映射实现数据直达;在GPU之间构建了以共享内存为中枢的高速流转机制,数据无需在应用层进行复杂的格式转换与回传,而是通过映射后的共享内存直接建立跨设备数据桥梁。这种以“地址共享替代数据搬运”的通信范式,使传统的“多次拷贝、逐级传递”通信范式演进为“一次生成、全链路直达”,实现了全场景的“零拷贝”闭环。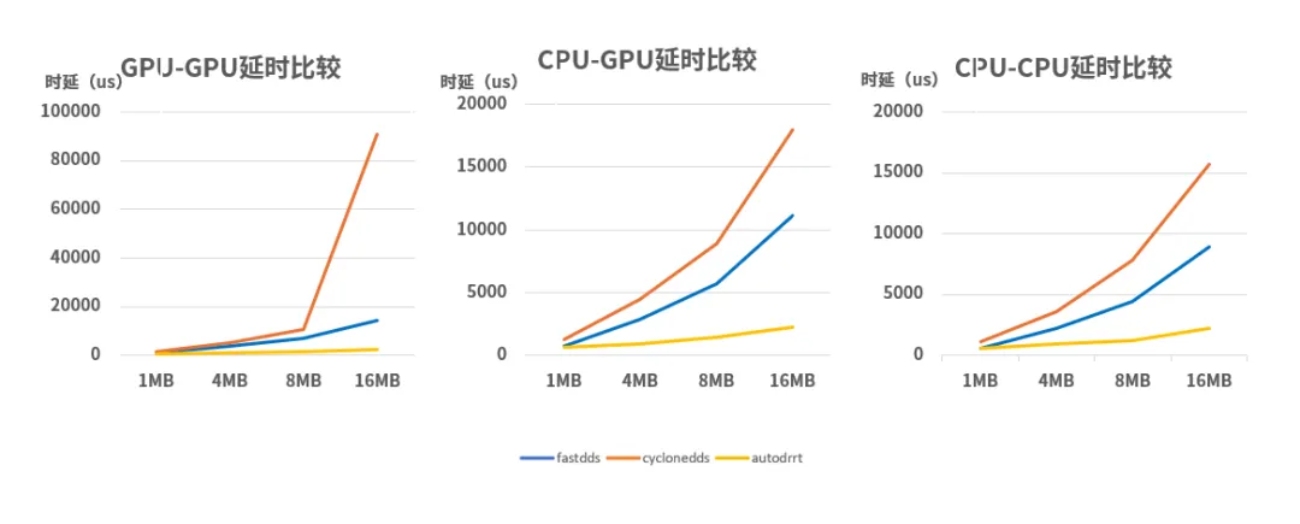
高性能通信框架下时延对比情况
在1MB至16MB的负载测试中,AutoDRRT 3.0展现出对传统中间件的代差优势:在16MB大数据流转时,其时延表现较FastDDS提升了4至5.6倍,较CycloneDDS最高提升近35倍。这种压倒性的性能增益彻底消解了数据传输层面的“软性延时”,实现了大数据负载下的微秒级确定性响应。
■ 调度革新,统一异构算力调度框架
AutoDRRT 3.0构建了一套面向多计算单元的异构算力调度机制,对CPU、GPU、AI等异构算力资源进行统一编排与精细化管理,避免因调度粗放或资源争用导致的算力空转与链路阻塞,系统在保障关键任务实时性的同时,显著提升整体算力利用率。
AutoDRRT 3.0在CPU侧,深度融合优先级与时间片轮转(RR)等调度策略,并结合精细化绑核控制,从系统层面避免资源争抢,确保逻辑控制与关键任务的实时性;在GPU侧,针对高负载推理场景,系统引入“优先级+流水线+全并行”的一体化调度架构:通过模型级优先级管理保障关键感知任务的算力供给;借助异步流水线调度实现数据处理与模型推理的重叠执行,消除计算空闲;同时协同GPU与 专用加速单元进行并行执行,根据算子特征进行任务分配与并行执行,最大化整体吞吐能力。该调度范式以保障实时性、追求吞吐率为核心原则,实现了多计算单元的高效协同,显著提升了端到端感知链路的执行效率与系统稳定性。
异构算力调度框架下时延对比情况
实测数据显示,异构算力调度框架解决了VLA大模型在车端的资源争用与响应阻塞,实现了执行效率与确定性的双重跨越,逻辑响应时延降低 31%,核心感知模型推理时延降低 30%,VLA 推理链路进一步压缩 28%,端到端时延稳定性显著提升,推理时延由108ms缩减至78ms,彻底消除算力空转。
此外,AutoDRRT已率先实现了对本土地平线征程6(J6)平台的深度原生支持,针对无人车场景打通了底层芯片异构算力到上层通用软件栈的全链路,完成了ROS + Autoware.ai 以及 ROS2 + Autoware.universe 的全栈原生适配,成为行业首个适配该平台的开源自动驾驶框架。基于J6域控+AutoDRRT,客户可直接在J6域控上实现方案的“开箱即用”与快速验证。覆盖无人配送与环卫小车等多元场景实现能力的快速平移与部署,助力无人车产品在全场景下缩短研发周期,抢占商业化落地先机。
 基于地平线J6域控AutoDRRT 3.0典型场景运行效果图
基于地平线J6域控AutoDRRT 3.0典型场景运行效果图
浪潮信息AutoDRRT 3.0,为业界提供首个面向 VLA 大模型、可在智驾域控平台运行的开源加速框架。它不仅验证了 VLA 大模型在车端实时闭环运行的工程可行性,也为自动驾驶从“端到端感知”迈向“全场景通用智能”提供了坚实的系统基础。
未来,浪潮信息将持续迭代 AutoDRRT 开源生态,推动 VLA 技术在乘用车与商用车辆等多元场景中的规模化落地,加速自动驾驶真正走向可复制、可量产、可演进的新阶段。
「开源地址 」
浪潮信息开源自动驾驶计算框架AutoDRRT 3.0
https://github.com/IEIAuto/AutoDRRT.git

 第七代服务器
第七代服务器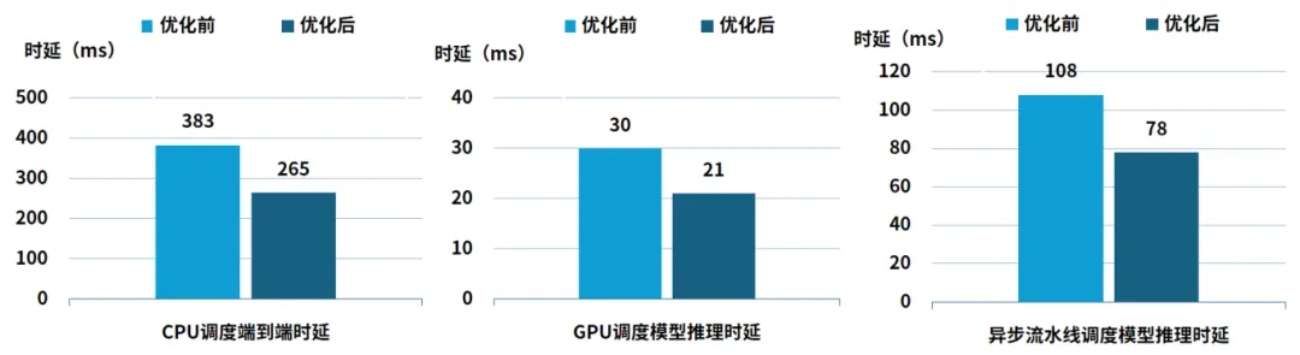














 访问 AIStore
访问 AIStore