过去一年,大模型推理能力的进化几乎沿着一条单向路径前进:更复杂的推理过程、更长的思维链、更“像人类”的自我反思。
在数学和科学推理等benchmark上,这条路径看起来无可挑剔。但当走向实际企业落地时,一个隐藏问题逐渐暴露:模型经常在得出正确答案后仍持续“反复思考”,导致大量算力被浪费在无效验证上。
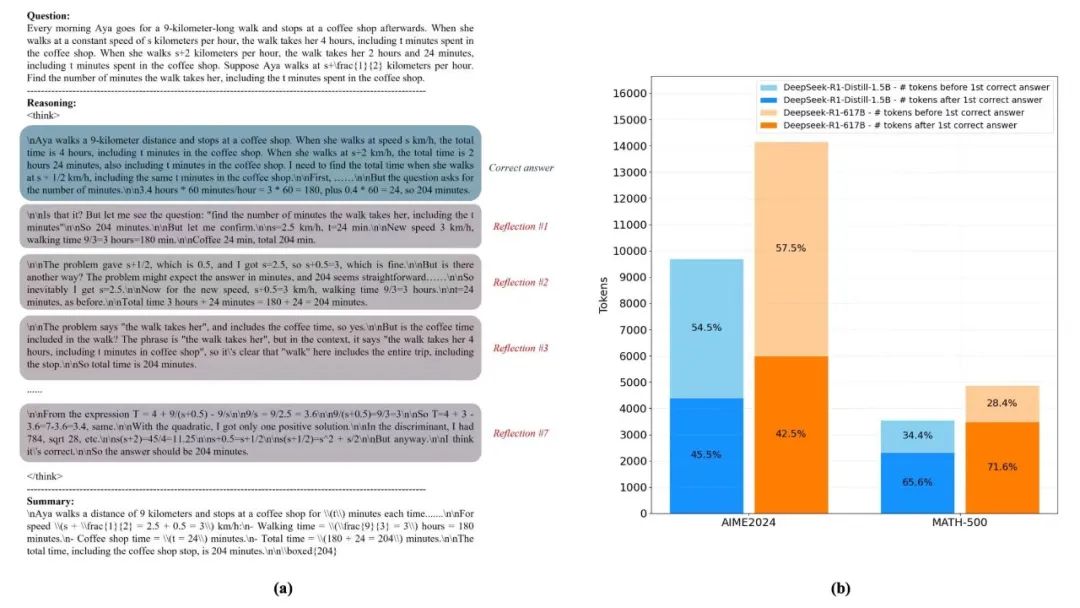 图 1:推理Token消耗分布示意
图 1:推理Token消耗分布示意
深色区域代表模型在已得到正确答案后的反思阶段,占比超过70%。
研究显示,在部分先进推理模型的数学与科学任务中,超过70%的Token消耗,发生在模型“已经答对,但仍在反思”的阶段。换句话说,模型真正用于形成正确结论的计算,只占了不到三分之一,其余大部分资源被用来“反复确认一件已经确定的事”。这正是企业在大模型落地过程中频繁遭遇却又难以精确定位的隐性成本来源:模型不是不够聪明,而是“想得太多”。
针对这一问题,YuanLab.ai团队在近期开源的Yuan3.0 Flash模型中,创新性地提出了RIRM(反思抑制奖励机制)与RAPO(反思感知自适应策略优化),通过训练机制引导模型在保持推理能力的同时,学会在恰当的时间停下来,从而实现推理效率的突破性提升。
论文链接:https://arxiv.org/abs/2601.01718
为什么大模型会“想太多”?
如果将大模型的推理过程类比为人类解题,问题会变得异常直观。一个成熟的专家,在确认结论成立后,往往会停止继续推演;而大量现有模型却会在已经得到正确答案后,继续反复检查、反复否定、反复验证。
这种行为并非偶然,而是与传统强化学习训练范式高度相关。长期以来,强化学习更多关注“结果是否正确”,而极少对“推理是否已经足够”进行约束。在训练信号的引导下,模型逐渐形成一种行为偏好:只要继续思考,就可能获得更高奖励。在学术环境中,这种倾向往往被解读为“推理更充分”;但在企业场景中,它直接转化为三类问题:推理Token不可控、系统响应延迟增加,以及在过度反思中反而引入错误判断。
Yuan3.0 Flash的技术创新,正是从这一行为层面的失衡入手,而不是简单地通过规则裁剪或输出限制来“压短答案”。
RIRM:通过奖励“思考过程”优化模型训练
RIRM(Reflection Inhibition Reward Mechanism,反思抑制奖励机制)的核心思想并不复杂,却极具突破性:模型不仅要为“答对”负责,也要为“什么时候停止思考”负责。
在传统训练中,只要最终答案正确,模型在中途经历了多少次自我否定、重复验证,几乎不会被区分对待。而RIRM首次明确引入了一条新的判断标准——当模型已经形成可靠结论后,继续反思是否还具有信息价值。
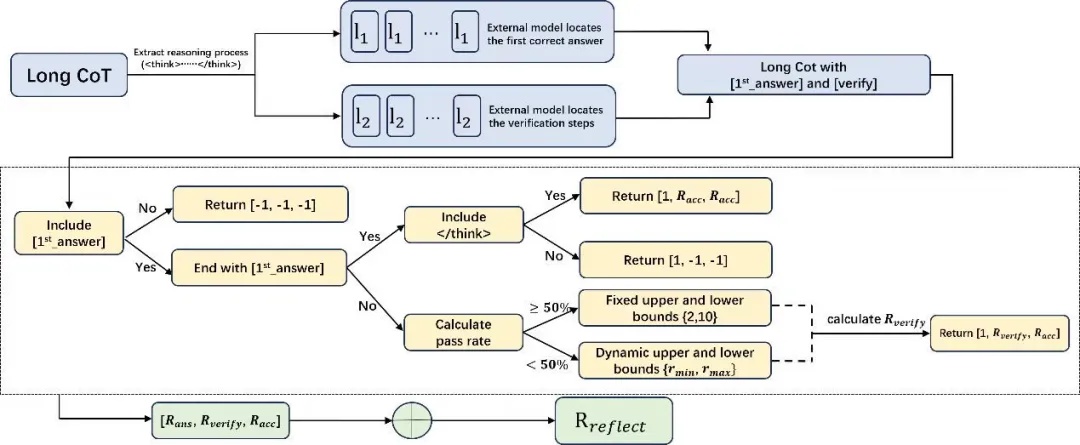 图 2:RIRM工作流程示意
图 2:RIRM工作流程示意
从首次正确答案识别到反思阶段奖励抑制的完整链路。
在训练过程中,系统会先定位模型推理里 “首次得出正确答案” 的节点,再针对该节点后的行为做反思次数的价值判定:如果后续步骤既没有新增证据或约束,只是重复已有逻辑,或是在缺乏信息的情况下反复推翻已验证结论,这类超出必要次数的反思则被标记为低价值(负价值)行为——通过这种方式,引导模型学会在合理的反思次数内完成答案验证。
这些反思行为不再被默认视为“更谨慎”,而是在奖励层面受到抑制。通过持续的强化学习训练,模型逐渐学会区分两种状态:什么时候需要继续推理,什么时候已经可以停止。
 图 3:RIRM训练前后Token消耗对比
图 3:RIRM训练前后Token消耗对比
反思阶段(深色部分)显著缩减,而首次解题阶段基本保持不变。
这种机制的关键意义在于,它并不是简单地限制输出长度,而是从根本上改变了模型对“好推理”的理解标准——高质量推理不等于更长的推理,而等于恰到好处的推理。
实验结果也印证了这一点。在数学、科学等复杂推理任务中,引入RIRM后,模型在准确率保持甚至提升的同时,推理Token消耗显著下降,最高可减少约75%。更重要的是,反思阶段的无效计算被大幅压缩,模型不再陷入“越想越多、越想越乱”的行为模式。
RAPO:反思感知的自适应策略优化算法
然而,仅靠对推理行为的抑制,并不足以支撑一个稳定、高效的企业级模型训练。Yuan 3.0 Flash所引入的RAPO(Reflection-aware Adaptive Policy Optimization,反思感知自适应策略优化)并非一次局部技巧的优化,而是对强化学习训练框架的一次系统性改进:从数据采样效率、到学习目标、到推理过程评估(RIRM),同时兼顾训练效率、训练稳定性及推理效率,使模型能够在多任务、异构场景中形成更具实用价值的策略。
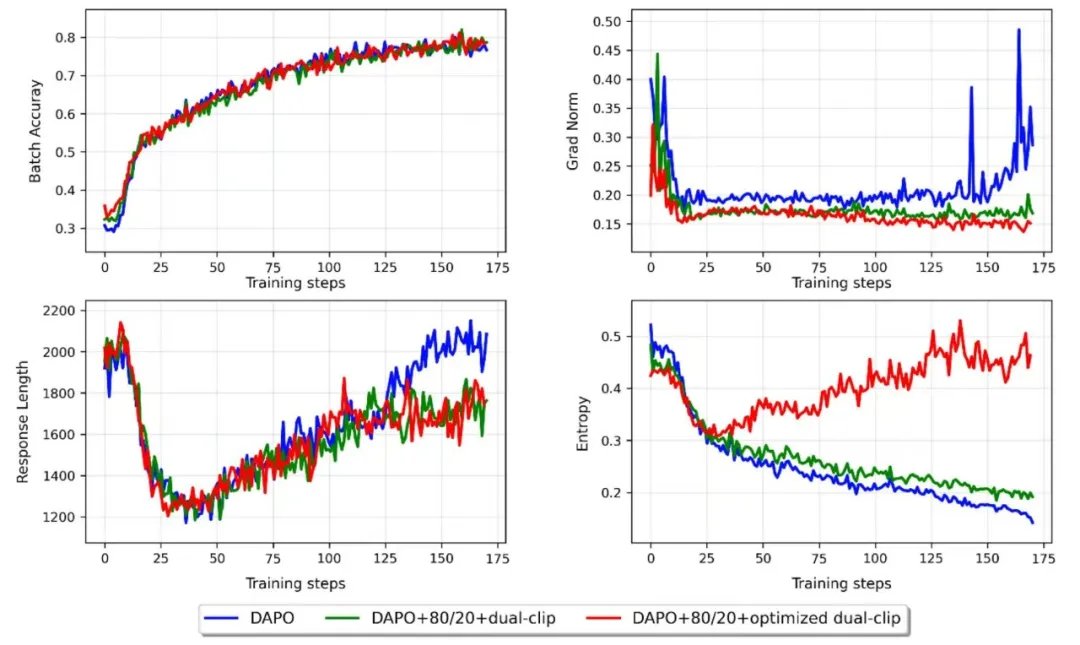 图 4:不同强化学习策略下的训练稳定性对比
图 4:不同强化学习策略下的训练稳定性对比
引入RAPO后,训练过程中的梯度波动显著减小。
RAPO通过自适应采样、梯度稳定性控制等机制,显著减少了强化学习阶段的过度数据采样,有效抑制了训练过程的梯度波动。在大规模MoE模型上,这种改进尤为关键——实验显示,RAPO可使整体训练效率提升超过 50%,在保证模型能力提升的同时,大幅缩短训练周期。
更重要的是,RAPO与RIRM在设计上是协同的。RAPO决定模型“如何学习”,而 RIRM 明确模型“学到什么程度该停”。前者提供稳定高效的学习框架,后者则为推理行为划定边界,两者叠加,才使“想对就停”真正成为模型的默认行为,而非例外情况。
“更少算力、更高智能”如何落到企业真实场景中
在架构层面,Yuan3.0 Flash采用稀疏MoE设计,在推理时仅激活少量专家,降低单次推理的计算开销;而在行为层面,RAPO与RIRM进一步确保这些算力被用于真正有价值的判断,而非冗余反思。
这种组合效应,在企业高频场景中表现尤为明显。在RAG场景下,模型能够更快聚焦于检索到的关键信息,而不是围绕同一内容反复展开解释;在复杂表格理解中,推理路径更加直接,不再被冗余验证拖慢;在长文档分析中,模型避免了层层递归式总结,显著提升了响应效率。
对企业而言,这意味着一个非常关键的变化:默认推理模式本身就已经足够可靠。无需额外开启高成本的“深度思考模式”,模型就能在大多数业务任务中保持稳定、可控的表现,也就是更快、更准、更省。
Yuan3.0 Flash的技术实践表明:当大模型已经具备足够的推理能力后,真正稀缺的,不再是“让它想得更多”,而是“让它知道什么时候该停”。
RIRM通过奖励机制约束无效反思,解决了“想得太多”的问题;RAPO通过高效、稳定的强化学习策略,解决了“学得太慢、学得不实用”的问题。两者共同构成了一条面向企业级落地的现实路径——在不牺牲能力的前提下,实现更低成本、更高效率的智能系统。
「开源地址 」
代码开源链接
https://github.com/Yuan-lab-LLM/Yuan3.0
论文链接
https://arxiv.org/abs/2601.01718
模型下载链接
1) Huggingface:
https://huggingface.co/YuanLabAI/Yuan3.0-Flash
https://huggingface.co/YuanLabAI/Yuan3.0-Flash-4bit
2) ModelScope:
https://modelscope.cn/models/Yuanlab/Yuan3.0-Flash
https://modelscope.cn/models/Yuanlab/Yuan3.0-Flash-int4
3)wisemodel:
https://www.wisemodel.cn/models/YuanLabAI/Yuan3.0-Flash
https://www.wisemodel.cn/models/YuanLabAI/Yuan3.0-Flash-4bit

 第七代服务器
第七代服务器













 访问 AIStore
访问 AIStore